LLMLingua
Effectively Deliver Information to LLMs via Prompt Compression
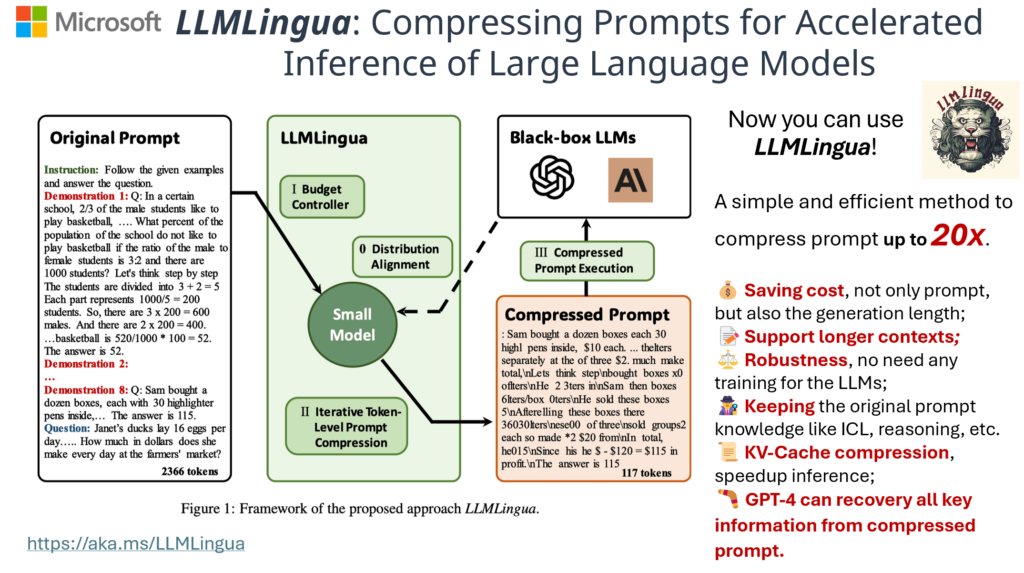
LLMLingua
Identify and remove non-essential tokens in prompts using perplexity from a SLM
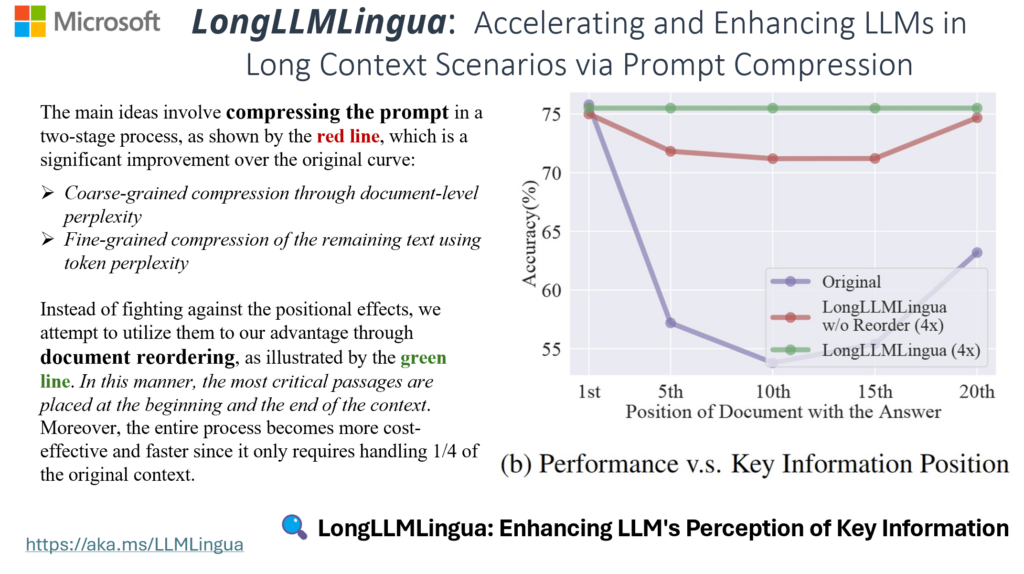
LongLLMLingua
Enhance long-context information via query-aware compression and reorganization
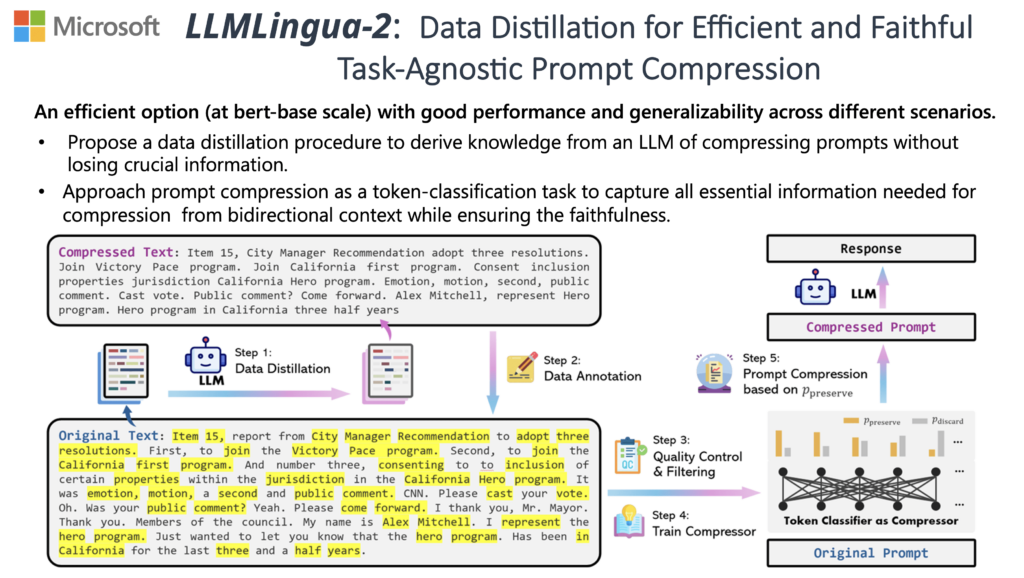
LLMLingua-2
Utilize data distillation to learn compression targets for efficient and faithful task-agnostic compression
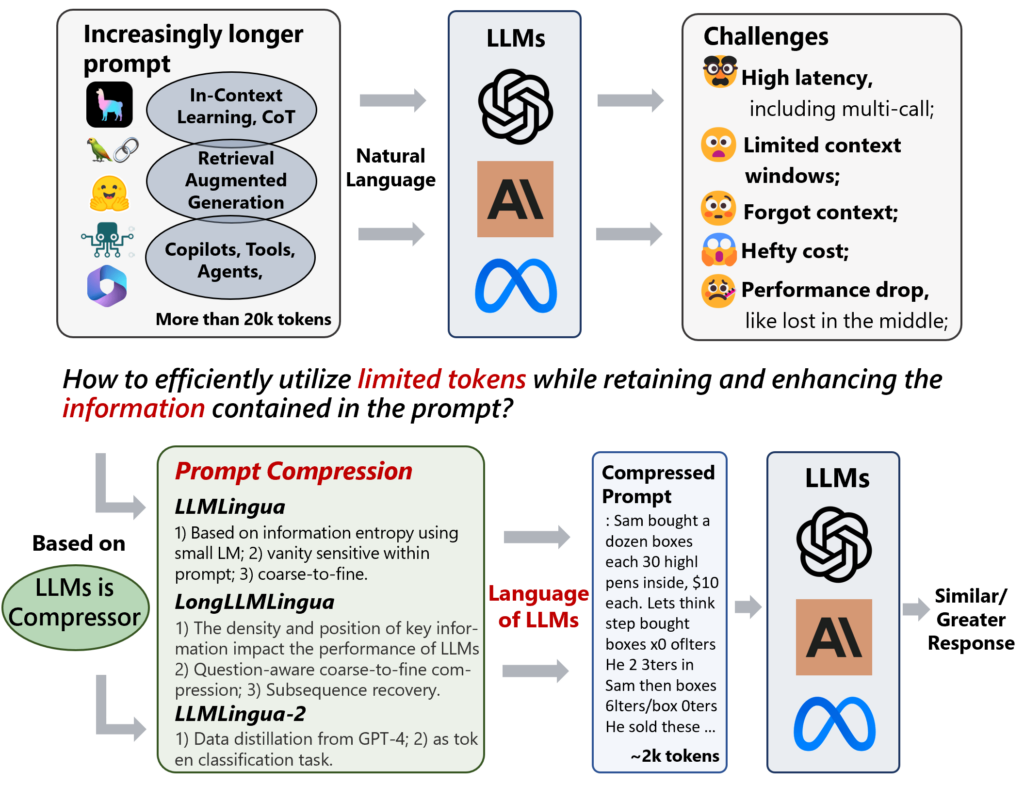
Large language models (LLMs) have demonstrated remarkable capabilities and have been applied across various fields. Advancements in technologies such as Chain-of-Thought (CoT), In-Context Learning (ICL), and Retrieval-Augmented Generation (RAG) have led to increasingly lengthy prompts for LLMs, sometimes exceeding tens of thousands of tokens. Longer prompts, however, can result in 1) increased API response latency, 2) exceeded context window limits, 3) loss of contextual information, 4) expensive API bills, and 5) performance issues such as “lost in the middle.”
Inspired by the concept of “LLMs as Compressors,” we designed a series of works that try to build a language for LLMs via prompt compression. This approach accelerates model inference, reduces costs, and improves downstream performance while revealing LLM context utilization and intelligence patterns. Our work achieved a 20x compression ratio with minimal performance loss(LLMLingua), and a 17.1% performance improvement with 4x compression (LongLLMLingua). LLMLingua-2 (opens in new tab), a small-size yet powerful prompt compression method trained via data distillation from GPT-4 for token classification with a BERT-level encoder, excels in task-agnostic compression. It surpasses LLMLingua in handling out-of-domain data, offering 3x-6x faster performance.
This page is for research demonstration purposes only.
If you are interested in our ideas, please feel free to use LLMLingua and communicate with us.
News
- 🦚 We’re excited to announce the release of LLMLingua-2, boasting a 3x-6x speed improvement over LLMLingua! For more information, check out our paper (opens in new tab), visit the project page (opens in new tab), and explore our demo (opens in new tab).
- 👾 LLMLingua has been integrated into LangChain (opens in new tab) and LlamaIndex (opens in new tab), two widely-used RAG frameworks.
- 🤳 Talk slides are available in AI Time Jan, 24 (opens in new tab).
- 🖥 EMNLP’23 slides are available in Session 5 (opens in new tab) and BoF-6 (opens in new tab).
- 📚 Check out our new blog post (opens in new tab) discussing RAG benefits and cost savings through prompt compression. See the script example here (opens in new tab).
- 👨🦯 Explore our ‘./examples’ (opens in new tab) directory for practical applications, including LLMLingua-2 (opens in new tab), RAG (opens in new tab), Online Meeting (opens in new tab), CoT (opens in new tab), Code (opens in new tab), and RAG using LlamaIndex (opens in new tab).
Insights
- Natural language is redundant, amount of information varies.
- LLMs can understand compressed prompt.
- There is a trade-off between language completeness and compression ratio. (LLMLingua)
- GPT-4 can recover all the key information from a compressed prompt-emergent ability. (LLMLingua)
- The density and position of key information in a prompt affect the performance of downstream tasks. (LongLLMLingua)
- GPT-4 can perform high quality, extractive prompt compression using carefully designed instruction and chunking. (LLMLingua-2)
- Prompt compression can be formulated as a token classification problem and accomplished by a Bert size model. (LLMLingua-2)
- Prompt compression can be formulated as a token classification problem and accomplished by a Bert size model. (LLMLingua-2)
For more details, please refer to the project pages, LLMLingua (opens in new tab), LongLLMLingua (opens in new tab), and LLMLingua-2 (opens in new tab).