
Project Parade
Established: October 17, 2014
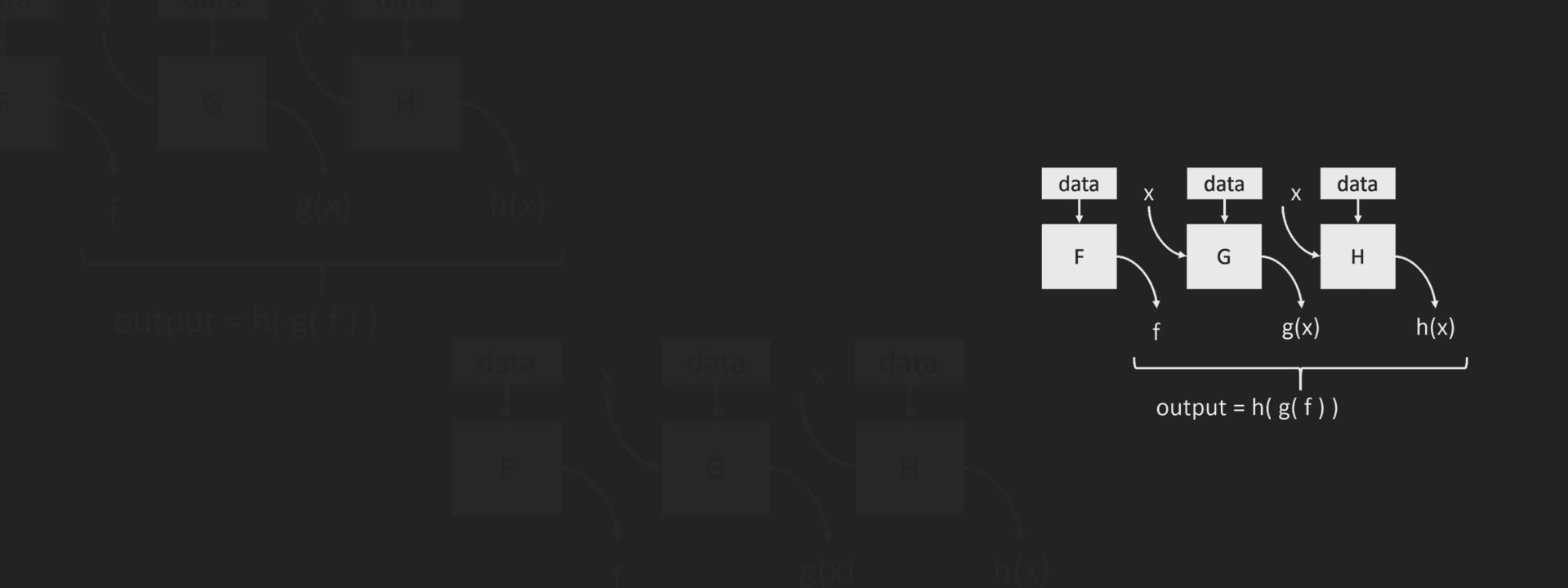
Project Parade is a novel approach to parallelizing a large class of seemingly sequential applications wherein dependencies are, at runtime, treated as symbolic values. The efficiency of parallelization, then, depends on the efficiency of the symbolic computation, an active area of research in static analysis, verification, and partial evaluation. This is exciting as advances in these fields can translate to novel parallel algorithms for sequential computation.
People
Madan Musuvathi
Partner Research Manager