

Project Rumi
Multimodal paralinguistic prompting for large language models
Multimodal paralinguistic prompting for large language models
Large language models (LLMs) are powerful neural networks that generate natural language with demonstrated value across a wide range of domains. They are revolutionizing many aspects of human society and culture including introducing a “whole new interaction model between humans and computers, turning natural language into the most powerful productivity tool on the planet.”1
However, LLMs also have limitations: they may not always understand the context and nuances of a conversation. Their performance also depends on the quality and specificity of the user’s input, or prompt. The data that the user inputs into the LLM is a lexical entry, which does not comprehensively represent the nuances of human-to-human interaction; it is in fact missing all the paralinguistic information (intonation, gestures, facial expressions, and everything besides the actual words) that contribute to the meaning and intentions of the speaker. This can lead to misinterpretation, misunderstanding, or inappropriate responses from the LLM. Project Rumi incorporates paralinguistic input into prompt-based interactions with LLMs with the objective of improving the quality of communication. Providing this context is critical to enhancing LLMs capabilities in this “AI as a copilot” era.
Our current system leverages separately trained vision and audio-based models to detect and analyze non-verbal cues extracted from data streams. The models assess sentiment from cognitive and physiological data in real time, generating appropriate paralinguistic tokens to augment standard lexical prompt input to existing LLMs such as GPT4. This multimodal, muti-step architecture integrates seamlessly with all pretrained text-based LLMs to provide additional information on the user’s sentiment and intention that is not captured by text-based models, augmenting the prompt with the richness and subtlety of human communication to bring human-AI interaction to a new level.
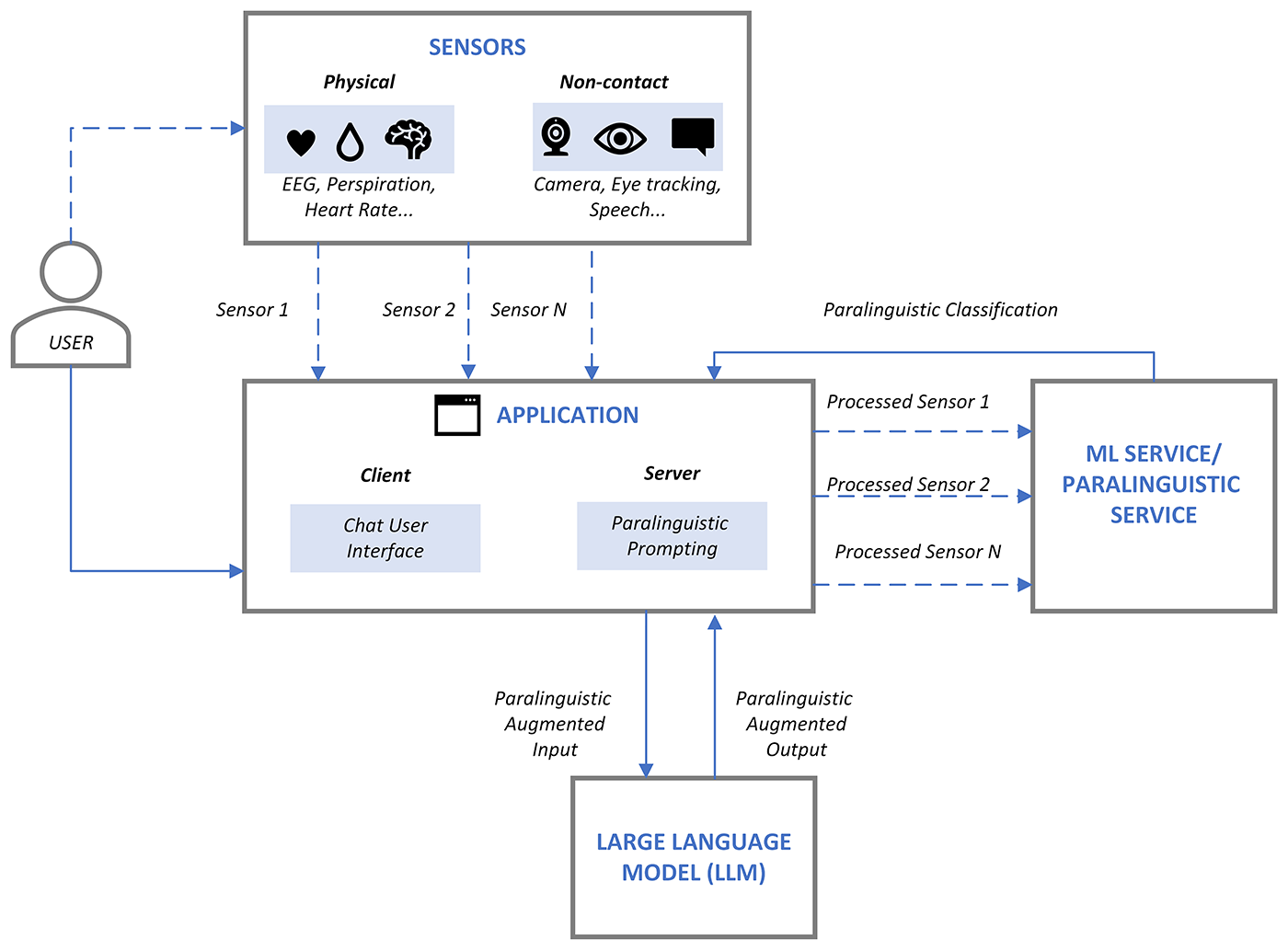
Future explorations include improving performance of existing models and incorporating additional signals like HRV (heart rate variability) derived from standard video, and cognitive and ambient sensing. Conveying unspoken meaning and intention is an essential component in the next generation of AI interaction.