

Sho is an interactive environment for data analysis and scientific computing that lets you seamlessly connect scripts (in IronPython) with compiled code (in .NET) to enable fast and flexible prototyping. The environment includes powerful and efficient libraries for linear algebra as well as data visualization that can be used from any .NET language, as well as a feature-rich interactive shell for rapid development. Sho is available under the following licenses: Sho for IronPython 2.6 license and Sho for IronPython 2.7 license. See the Installers page for more details about the two versions.
Links
-
There are two versions of Sho available; one built on IronPython 2.6 and one built on IronPython 2.7. Depending on your usage scenario, you will want one or the other; the information below will help you decide.
Sho 2.1 on IronPython 2.7*
This is the version you’ll want if you plan to use the Python Tools for Visual Studio IDE for Sho, and/or you want the latest version of IronPython (2.7). Note that since this latest version of IronPython is distributed from codeplex under a different license, this version of Sho does not ship with the IronPython bits; you’ll have to install IronPython 2.7 (from codeplex) (opens in new tab) separately before installing Sho. An advantage of installing IronPython in this way is that the Python standard libraries will be available to you as well. Note that if you’re planning to use PTVS you need to uncheck the option in the 2.7 installer for the Visual Studio components; that option conflicts with PTVS.
Installer for Sho 2.1 on IronPython 2.7 (requires separate IronPython 2.7 (opens in new tab) install)
Sho 2.1 on IronPython 2.6*
This version is fully self-contained, in that the essentials of IronPython 2.6 are included (just binaries, not the standard libraries; if you want the latter you’ll need to do an install of IronPython 2.6 from codeplex and point your Sho path to the libraries). This is the version you’ll want if the IronPython 2.7 license on codeplex is not compatible with your needs. This is also the version you’ll want if you want to use the HPC or Azure packages for Sho – we’ll be upgrading those in the near future to work with both versions, but for now they will only work with the IronPython 2.6 version.
Installer for Sho 2.1 on IronPython 2.6 (self-contained)
Requirements
OS: Windows 7, Server 2008, Vista, or Server 2003.Dependencies (Sho 2.1 for IronPython 2.6): .NET 4.0 or higher.Dependencies (Sho 2.1 for IronPython 2.7): .NET 4.0 or higher, IronPython 2.7.
*This library includes parts of the Intel Math Kernel Library. For more information about the Intel Math Kernel Library, please visit http://software.intel.com/en-us/intel-mkl/ (opens in new tab) .
-
Using Sho with Python Tools for Visual Studio (PTVS)
If you’re looking for a great integrated development environment (IDE) for Sho, Python Tools for Visual Studio (PTVS) is a perfect fit. PTVS is a plugin for Visual Studio 2010; you can get the free VS Shell if you don’t have Visual Studio already. PTVS gives you an interactive REPL with intellisense, great editing capabilities such syntax highlighting, automatic indents, intellisense, etc., as well as Python debugging, with some project management features to boot. A screenshot of using Sho with PTVS is below.
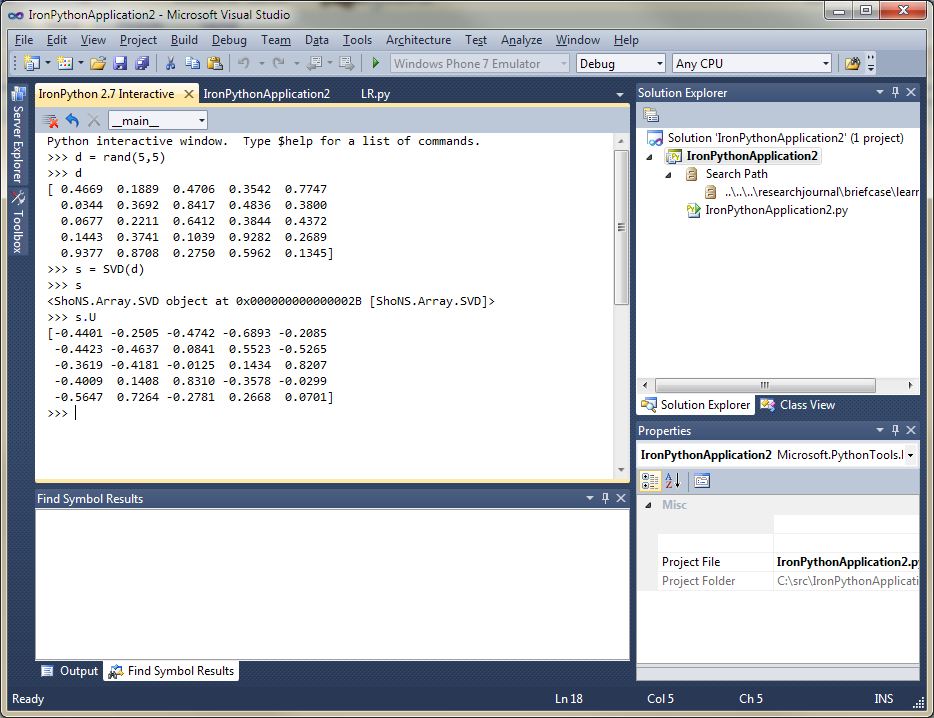
Downloading and Installing PTVS and Sho
- You’ll first need to install IronPython 2.7 from the IronPython page (opens in new tab). When running the installer, be sure to uncheck the “Visual Studio” options; those conflict with PTVS. Note that PTVS debugging/interactive windows will not work properly with earlier versions of IronPython (pre 2.7) – you can still edit code and do .net debugging, but for the full experience you’ll want IronPython 2.7.
- Next install Sho 2.0.5 (the version targeted to IronPython 2.7). You’ll need to first uninstall any previous Sho installations.
- Download and install the PTVS plugin from the PTVS project page (opens in new tab). Note that if you don’t have Visual Studio 2010 already, you can see various means of getting it (including several free options) in the “Getting Visual Studio” section of the PTVS install page (opens in new tab).
- Start Visual Studio, and go to Tools->Options->Python Tools->Interpreter Options. Set the “Default Interpreter” to be “IronPython 2.7.” If you’re on a 64-bit machine and want to use all of your memory for Sho computations, set it to “IronPython 64-bit 2.7”
Setting up Sho for PTVS
If you’re a regular Sho user, you’ll probably want to add the importing of the Sho libraries directly into the startup of the PTVS. To do this, you’ll first create a startup file, which I like to call “shoptvs.py” – the contents are below:
# shoptvs.py - Sho startup file for PTVS
import syssys.path.append("c:/Program Files//sho 2.0//sho")from sho import *Note that you’ll have to set the path to point to the “shoshodir”, which you can find by evaluating shoshodir in the Sho console. To specify this as the startup file for the IronPython interpreter, go to Tools->Options->Python Tools->Interactive Windows, and under “Startup Script” specify the full path to shoptvs.py (or whatever you chose to call it). If you don’t want to create/use this startup file, you can manually execfile shoptvs.py or just include the lines above in any scripts from which you want to use Sho commands or libraries.
You can now click on Tools->Python Tools->IronPython 64-bit 2.7 Interactive, and you’ll get a new REPL with all the Sho commands at your fingertips.
Debugging Sho code from PTVS
There are two styles of debugging for IronPython – Python debugging and .NET debugging. Python debugging lets you look inside Python classes and examine variables, just as you would with pdb, but doesn’t let you step into .NET code. .NET debugging does let you step into and examine .NET code, but gives you a more limited Python debugging experience – for instance, members of Python classes will appear as they do in .NET, as part of dictionary, as opposed to the class structure you’d see in Python debugging. In short, if you’re mostly debugging Python code, you’ll likely want Python debugging; if you’re mostly debugging C# (or mixed mode code), you’ll want to use .NET debugging.
PTVS is focused on Python debugging; if you want to do .NET debugging see “Using PTVS with the Sho Console” below. To do Python debugging, simply set breakpoints in your code (F9) and then run commands from the Python Interactive window; when your breakpoints are hit, execution will pause, and you can investigate variables, step through, etc.
Using PTVS with the Sho Console
If you’re doing mixed mode (Python and C#) development or just prefer the Sho Console for your interactive sessions, you can still take advantage of PTVS’s fantastic editor as well as .NET debugging. As described above, .NET debugging lets you set breakpoints in both Python and C# code, step into C# or Python code, etc., at the cost of not being able to look inside Python objects with the same convenience as Python debugging (above).
To debug code in Sho Console, you’ll need to first attach to the process via Debug->Attach to Process in Visual Studio. This will bring up a list of processes and their IDs; pick the appropriate “shoconsole.exe” process. If you have more than one you can evaluate System.Diagnostics.Process.GetCurrentProcess().Id in the console to find out the Process ID for the one you wish to debug. You can then load up the relevant Python and C# files you wish to debug in Visual Studio, and set breakpoints wherever you wish. When you execute code in the console that results in one of these breakpoints being hit, execution will pause and control will go to Visual Studio; at this point you can step through code, step into code, etc., as you normally would in VS.
-
Sho Console showing matrix manipulation

“Intellisense”-like behavior
Available for class, method, and filename; activated by hitting
in the console 
Using doc() to Inspect Objects
>>> f = System.Windows.Forms.Form()>>> doc(f)

Plotting a Sine Wave
>>> x = drange(0, 2*PI, 0.05)>>> plot(x, sin(x))

Computing a Word Histogram
>>> txt = System.IO.File.ReadAllText("./declarationofindependence.txt")>>> table = System.Collections.Hashtable()>>> for word in txt.split(): if table.ContainsKey(word): table[word] += 1 else: table[word] = 1>>> pairs = zip(table.Keys, table.Values)>>> elts = sorted(pairs, lambda a, b: a[1] < b[1])[:10]>>> words, counts = zip(*elts)>>> bar(words, counts)

Creating a Simple GUI
>>> f = System.Windows.Forms.Form()>>> b = System.Windows.Forms.Button()>>> f.Controls.Add(b)>>> b.Text = "Hello World">>> b.Location = System.Drawing.Point(250,100)>>> f.Width = 561>>> def printhello(sender, evtinfo): print "Hello World!" >>> b.Click += printhello>>> f.ShowDialog()

-
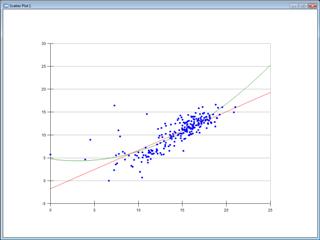
Plotting/Analyzing SQL Data
This is a short, canonical demo of doing Data-Centric Development from Sho: pulling data from an enterprise source (SQL), visualizing it, and doing some analysis on it. In this case, we fit lines and curves to data of population vs. area for various countries.

Web Search with Speech
This demo shows how a tiny bit of Sho can be used to mix powerful platform components: in this case, we use Windows’ speech recognition engine to send queries to bing. [41 lines of code]

Sticky Sorter Prototype
This is an application built in Sho that allows for arranging and editing sticky notes on a virtual canvas, a key functionality for user experience researchers organizing observation data. It was an initial, fully-functioning prototype that was used as the basis for the “StickySorter” application now available from Office Labs. [1000 lines of code]

A Data Oscilloscope for Microsoft Surface
This is an example of using Sho as a “data oscilloscope,” i.e., to visualize the values of live data. in this case, values from a Microsoft Surface application are being shown and updated in real-time using Sho plot objects on a second monitor.
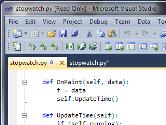
Debugging Sho Code with Visual Studio 2010
This video shows how you can edit and debug Sho code with Visual Studio 2010 along with IronPython Tools (opens in new tab), available from IronPython.net. The video shows how to set breakpoints, step through code, inspect locals, and more. [highres version, 61MB]
-
Azure (Cloud Computing) – [download] [documentation]
Enables parametric sweeps on Microsoft Azure directly from the Sho console. Python functions defined in modules on the local filesystem can be run remotely and return results to the local instance; relevant dependencies and data can be specified for more complex computations.
HPC (Cluster Computing) – [download] [documentation]
Enables parametric sweeps on Microsoft HPC clusters directly from the Sho console. Python functions defined in modules on the local filesystem can be run remotely and return results to the local instance; relevant dependencies and data can be specified for more complex computations.
Package installation instructions:
- Save the .zip file from the packages page to a temporary directory
- Extract the contents of that zip file to your package directory. If you’re not sure where that is, you can find out from the Sho console by typing>>> shopackagedir
- Restart* your Sho console
*Note: If you really don’t want to restart Sho, you can import the name of the package directory name; for instance, for the Optimizer package, import Optimizer.
-
HPC Package Documentation
Introduction
The HPC package lets you run Sho functions on an HPC cluster for parameter sweeps and related scenarios. In its most basic form, you specify a function which takes a couple of inputs, one of which will be the same for all remote instances, one of which will be one element of a list that you’ll also pass in. Advanced features let you specify data and output directories that will be copied to/from the cluster, as well as the ability to reconstitute a past cluster session from its output directory.
To use this package, you will have to have access to an HPC cluster, know the name of the headnode, and know/have read/write access to your personal working directory on the HPC cluster. Your cluster administrator should be able to give you all of this information.
Functions
- session = clusterrun(cluster, fn, data, paramlist, inDir=None, outDir=None, includeFilter=None, verbose=False)session = clusterrun(cluster, fn, data, paramlist, inDir=None, outDir=None, includeFilter=None, verbose=False)FN is a function (defined in some .py file) with two, three, or four arguments. On the cluster, when FN is called, the first argument will be DATA; the second argument will be an element from PARAMLIST. CLUSTERRUN finds the directory which contains the .py file in which FN is defined (we’ll refer to this as FNMODULE), then copies all .py and .dll files in that directory (and its subdirectories, recursively) to the cluster. Note that DATA and the elements of PARAMLIST must be of a type that is defined for a new instance of Sho that has only imported FNMODULE.INDIR is a local directory that contains additional data your function may need; if INDIR is defined, it will be copied to the cluster; the cluster-accessible location will be the third argument to FN.OUTDIR is a local directory; if specified, FN will get a fourth argument, a directory, to which the instance can write output information. When the command terminates, files in that directory will be copied back to OUTDIR on the local machine, in a subdirectory that is the session ID. Note that files written to this directory should have unique names for each instance, since they will all be copied to one directory.INCLUDEFILTER is a list of additional file types and names (beyond the default .py and .dll) that will be copied from the directory containing the module defining FN, as well as its subdirectories. Example: includeFilter=[“*.cs”, “*.pl”, “foo.txt”]SESSION is an object that identifies this job, and is an argument you can use to the clustergetresults() function once clusterrun has returned. SESSION also contains the working directory for the job (SESSION.WorkDir) as well as the session ID (SESSION.id)
- cl = clustersetup(HEADNODE,WORKDIR) Sets up a cluster for use, including creating the working directory and installing the current version of Sho. HEADNODE is a string specifying the name of the the head node; WORKDIR in the path to the working directory for your account on the cluster. The running version of Sho will be copied to your working directory in the directory “sho”, but if it is already there it will not be recopied.Returns a Cluster object cl, where cl.WorkDir is the working directory
- session = clustersession(SESSIONDIR)Reconstitutes a session from a session working directory. For instance, if you run an experiment and want to look at the results later, you can save the working directory (SESSION.WorkDir) from a cluster execution, and then use clustersession() to reconstitute it and examine the results. clustersession does not require access to the cluster as long as you have the
Walkthrough
# setup>>> cl = clustersetup(‘HEADNODENAME’,’//FILESERVER/YOURWORKDIR’)# note that your actual working directory, “YOURWORKDIR” may have your username or other info tacked onto the base workdir, e.g., //FILESERVER/BASEWORKDIR/LOCATION/USERNAME; check with your system administrator for details.
# write a function in a file, for instance, I have a function addstuff in file rctest.py>>> addpath(“blah/foo/blah/foo”)>>> import rctest>>> rctest.addstuff(3,4)7
# now run it on the cluster and get the results>>> session = clusterrun(cl, rctest.addstuff, 10, [1,2,3,4,5])>>> session.getresults()Dictionary[int, object]({0 : 11, 1 : 12, 2 : 13, 3 : 14, 4 : 15})
# explore the job’s working directory to look at stdout and stderr and other output>>> session.Workdir‘//FILESERVER/YOURWORKDIRsession-9dbd860b-e141-4dd0-9896-0cc470640ff7’
# now let’s say you’re recovering a past experiment whose results are in some directory – note the dir doesn’t have to be on the cluster, you could have copied it somewhere local to keep it around>>> session = clustersession(‘//FILESERVER/YOURWORKDIR/session-eb821858-b00f-4e6b-8f90-76f92838c9d6’)>>> session.getdata()10>>> session.getparams()[1,2,3,4,5]>>> session.getresults()Dictionary[int, object]({0 : 11, 1 : 12, 2 : 13, 3 : 14, 4 : 15})
-
Azure Package User Guide
The Azure Parameter Sweep package is an easy-to-use package that allows you to parallelize embarrassingly-parallel code over a number of Sho instances running in Azure. It is especially well-suited to parameter sweeps.

Installation and setup
In order to use the Azure package, your Azure administrator must first follow the directions in Admin Guide to get everything up and running on the cloud.
To install the package, simple copy the package directory to your Sho packages directory.

In order to use the package, it will need to know a couple of pieces of information about the Azure environment the Sho instances are running on. The following environment variables should contain the authentication information for your deployment. Ask your administrator for the values to set:
SHOAZUREACCOUNT =
SHOAZUREKEY =
Usage
The parameter sweep package uses work functions that take two arguments: one “data” and one “parameter” value:
def workfn(data, param): ...
When you tell the package to run your work function in the cloud, it uses a single “data” value common to all of the various instances, and a list of parameter values, which are distributed among them. Here is an example showing how to use the package to distribute a very simple work function over a list of parameter values:
Simple example
For this simple example, we are going to use a very simple predefined work function that simply adds the data value to the parameter value.
>>> import paramsweep # import the paramsweep package
>>> paramsweep.addDemoDir() # this adds the path to the test functions
>>> import paramsweeptest # paramsweeptest contains some demo functions
>>> session = paramsweep.run(paramsweeptest.add, 100, [1,2,3,4,5])
The run function returns a parameter sweep session object:
>>> print session
ParamSweepSession('2c574185-9cd3-4ba1-a6f3-9668424374a8')This session runs asynchronously on the cloud, leaving your Sho instance running so you can do work while you wait for it to finish. The isDone method will tell you if the session has finished. If it is, we can call getResults to get the results from each of the jobs. Alternately we can call the waitResults function, which blocks until it finishes, and then return the result values.
>>> session.isDone()
True
>>> session.getResults()
[101, 102, 103, 104, 105]
It is good practice to delete the server-side data associated with this session when you’re done.
>>> session.cleanup()
Of course, you aren’t limited to using integers as your data or parameter values:
>>> a = rand(4,4) # This is a Sho array
>>> session = paramsweep.run (paramsweeptest.multiply, a, [1, 3, 5])
>>> for x in session.waitResults(): print x,"n"
[ 0.4669 0.1889 0.4706 0.3542
0.7747 0.0344 0.3692 0.8417
0.4836 0.3800 0.0677 0.2211
0.6412 0.3844 0.4372 0.1443]
[ 1.4006 0.5668 1.4117 1.0625
2.3240 0.1033 1.1076 2.5252
1.4509 1.1399 0.2030 0.6633
1.9235 1.1532 1.3116 0.4329]
[ 2.3344 0.9447 2.3528 1.7709
3.8734 0.1722 1.8460 4.2087
2.4182 1.8999 0.3384 1.1055
3.2058 1.9221 2.1859 0.7215]
In addition to the return values, you can get back the data and parameter values:
>>> session.getData()
[ 0.4669 0.1889 0.4706 0.3542
0.7747 0.0344 0.3692 0.8417
0.4836 0.3800 0.0677 0.2211
0.6412 0.3844 0.4372 0.1443]
>>> session.getParams()
[1, 3, 5]
If you are planning to run the same work function over and over again in different sessions, you can simplify things further by creating a “sweeper” function from it. The sweeper function takes your work function and returns a thing that will automatically sweep your function over the set of parameters, block until they’re done and return the results:
>>> adder = paramsweep.sweeper(paramsweeptest.add)
>>> adder(10, [1,2,3,4,5])
[11, 12, 13, 14, 15]
>>> adder(100, [1,2,3,4,5])
[101, 102, 103, 104, 105]
Note that this is equivalent to:
>>> session = paramsweep.run(paramsweeptest.add, 10, [1,2,3,4,5])
>>> session.waitResults()
[11, 12, 13, 14, 15]
More complex examples
Oftentimes, you will want to run multiple parameter sweep sessions over the same large dataset. Since it can take a long time to upload the data to the cloud, you may want to explicitly upload the data once. Then you can tell the Azure instances to use the persisted cloud data, rather than upload it each time. This example uses the “topnsvd” test function, which returns the n largest singular values from a matrix.
>>> import azureutils
>>> arr = rand(1000, 1000)
>>> blob = azureutils.pickleToBlob(arr)
>>> session = paramsweep.run(paramsweeptest.topnsvd, blob, [1,2,3,4])
>>> session.waitResults()
[[ 500.0264], [ 500.0264 18.0877], [ 500.0264 18.0877 18.0564],
[ 500.0264 18.0877 18.0564 17.9239]]
All of the examples we’ve shown so far run work functions that take objects as the parameters and produce output in the form of return values. However, many times it is easier to express your work function in terms of input and/or output files. For these kinds of applications, we allow you to optionally specify an inDir and outDir argument to your work function. In this case, your work function should be specified as follows:
def workfn(data, param, inDir, outDir): ...
If you specify an inDir variable, the contents of that local directory will be uploaded to the cloud and then downloaded to your instance. For instance, indirlist is a function that returns a list of the files in inDir (the data and param values are ignored, and set to 0 here):
>>> session = paramsweep.run(paramsweeptest.indirlist, 0, [0], inDir="C:/tmp/myindir")
>>> session.waitResults()
[['a.txt', 'b.txt']]
If you want to produce output as files, outdirtest is an example:
>>> session = paramsweep.run(paramsweeptest.outdirtest, "foo", [1,2,3], outDir="C:/tmp/outdir")
>>> session.waitDone()
>>> session.downloadOutDir()
>>> ls("C:/tmp/outdir")1.pickle 27 10/19/2010 5:38:33 PM
2.pickle 27 10/19/2010 5:38:33 PM
3.pickle 27 10/19/2010 5:38:33 PM
You can get a list of session objects that still store data on the cloud using the listSessions function, which will return a handle to all of the sessions started by you:
>>> for s in paramsweep.listSessions(): print s
ParamSweepSession('8aee1717-3d23-44b0-8033-21883a332f39')ParamSweepSession('c6be1ea5-189e-441a-9f31-09a87ffc7102')This is particularly useful if you forgot to clean them up:
>>> for s in paramsweep.listSessions(): s.cleanup()
Note that your work function must conform to one of the following forms, or it will not work:
def workFn(data, param): ...
def workFn(data, param, inDir): ...
def workFn(data, param, inDir, outDir): ...
Finally, you can retrieve any output text printed by your work function with the getOutputText() method on your session object:
>>> session.getOutputText()
[...]
Caching state and data
In order to make sure that one job doesn’t pollute the Sho environment and cause problems for subsequent jobs running on that Azure instance, the entire Sho environment is restarted between jobs by default. Also by default, the data value is re-downloaded for each job, so that and destructive changes one job makes doesn’t affect another job. Since both of these safeguards are frequently unnecessary and can take a significant amount of time, there are ways to disable them to get your jobs to run faster.
These options are controlled by setting special global variables in the main module of your work function. Setting the “can_reuse_state” variable to True tells the system that you can re-use the Sho instance between jobs from the same session. The “can_reuse_data” variable controls whether or not you can reuse the same data object between jobs. Finally, if you want to be able to share state and/or data values between different sessions, you can set the “state_token” variable to some unique value. Different sessions with the same “state_token” value will be able to reuse the Sho environment and data value as if they were jobs from the same session. Here is an example of the settings in the python file that contains the demo job functions:
paramsweeptest.py:
can_reuse_state = True
can_reuse_data = True
state_token = "parametersweeptest"
Storage Utilities
The paramsweep and auzreutils modules contain a number of useful utilities for dealing with Azure storage.
To store a data object in the cloud, call the azureutils.pickleToBlob() method:
>>> arr =
>>> blob = azureutils.pickleToBlob(arr)
This stores your data into a new blob with a unique name. If you want to pickle to data into a blob with a particluar name or at a particular URL, you can pass that in:
>>> azureutils.pickleToBlob(arr, blobname) # blobname is a filename or fully-qualified URL
In order to read the data back from the cloud, you can call the unpickle method:
>>> blob.unpickle()
If you don’t have a blob object, you can create one given the URI of an object in blob storage. Or, you can directly unpickle from a URI:
>>> blob = azureutils.BlobLocation("http://") >>> mydata = blob.unpickle()
or
>>> mydata = azureutils.unpickleBlob(http://
) Finally, to delete a pickled blob, call the delete method or call the deleteBlob function:
>>> blob.delete()
>>> azureutils.deleteBlob("http://...")You can retrieve a list of blobs you’ve pickled via the listPickleBlobs function, which returns a list of BlobLocation objects:
>>> azureutils.listPickleBlobs()
[
, ] Here are a few other useful functions:
uploadFile() – uploads a file into blob storage
downloadFile() – downloads a blob’s contents to a file
uploadDirectory() – uploads a directory into blob storage
downloadBlobDirectory() – downloads a directory of files from blob storage
Viewing diagnostic information
If you want to output diagnostic messages from your work function, first import the azureserverutil module, then call the tracemessage function. The message will be saved in Azure diagnostic message storage. Then, you can call the showLog method on your session object in order to view the messages.
def tracetest(data, param):
azureserverutil.tracemessage(str(data) + ": " + str(param))
Then, back at the console, call showLog to display the log messages:
>>> session = paramsweep.run(paramsweeptest.tracetest, "message with param value", [1,2,3])
>>> session.waitDone()
(wait a few minutes)
>>> session.showLog()

The results will be displayed in a Sho datagrid, with the results from each job grouped together. Note that there is a delay of a couple of minutes between when your work function calls tracemessage and when the corresponding log message is viewable. Passing in True as the optional second parameter to showLog will display internal trace messages that the service records, which can be useful when troubleshooting:
>>> session.showLog(True)

Alternately, if you want to show all recent diagnostic messages, regardless of which session they belong to, you can all the azureutils.showLog function. This can sometimes help you determine if the service is having problems. Be aware that the format of these diagnostic messages can make them difficult to read:
>>> azureutils.showLog(10) # show messages from the last 10 minutes
>>> azureutils.showLog(TimeSpan.FromHours(12))
-
Before you can use the Azure package, you’ll need to get an Azure account, so you can upload data and run code in the cloud. To get started, go to the Azure Offers page (http://www.microsoft.com/windowsazure/offers/) and select the package that is most appropriate for you . Note that you do not need SQL Azure access to use the Sho Azure package. Please see the following links for information on pricing for academic and NSF-funded work:
http://www.nsf.gov/cise/news/2010_microsoft.jsp (opens in new tab)
http://www.azurepilot.com/ (opens in new tab)
Server-side Installation and setup
Creating the Azure storage service
First, we’ll create the storage service that will be used to store all of our data and results in the cloud. Go to the Windows Azure service portal (http://windows.azure.com (opens in new tab)) and log in.

Then, click on “New Storage Account” in the ribbon:

When prompted, enter a URL to use to access your storage service (e.g., “myshodata”) and click the ‘Create’ button. Make a note of the prefix for this URL (the “myshodata” part) – users of the package will need to know this account name in order to use the service. The other piece of information is the primary access key associated with this service, which users will need in order to authenticate themselves. To find this, select the new storage service you just created and then click on the “View” button for the primary access key:

This will display the access keys:

Users of the service will have to set two environment variables, SHOAZUREACCOUNT, which will get the name of your storage service (e.g., myshodata), and SHOAZUREKEY, which will get the primary access key. You will also need to set these variables on any computer you wish to administer the Sho Azure package from.
Copying Sho to the Cloud
Now that you have created the storage service and set your SHOAZUREACCOUNT and SHOAZUREKEY environment variables, you’ll need to copy a Sho installation to the cloud. The simplest way to do that is to run the Sho console and run the uploadSho() function from the Azure package:
Sho 2.0.4 on IronPython 2.6.1 (), .NET 4.0.30319.1 and MKL 10.3.
Includes parts of the Intel Math Kernel Library for Windows.
>>> azureutils.uploadSho()
This may take quite a long time. When it’s done, you’re ready to create the hosted service and upload the parameter sweeper.
Creating the Hosted service
Next, we’ll create the Azure compute service that the actual code will run on. In preparation for this, we must first load the ServiceConfiguration.cscfg file from the Publish directory in the Azure package into a text editor. Then replace
and with your account name and key in the highlighted lines: Now that you have edited the configuration file to be appropriate for your deployment, let’s create a new hosted compute service and upload the deployment. First, click on the “New Hosted Service” button from the Windows Azure portal:

This will bring up the “Create a new Hosted Service” dialog box. In this screen, you’ll have to make up a name and URL for your hosted service.

In addition, you can upload the deployment package (and its corresponding configuration file that you edited above) now. Choose “Browse Locally…” and point the file dialog at the .cspkg and .cscfg files in the Publish directory inside you Azure package directory (i.e., SHODIR/packages//azurePublish, where SHODIR is you Sho installation directory). Note that if you keep the “Start after successful deployment” box checked, the deployment start running in the cloud and you will start accruing usage charges!
Client-side installation and setup
To install the package, first copy the package directory to your Sho packages directory.
Then, set the following environment variables to the values you noted above:
SHOAZUREACCOUNT The name of the storage account you created (myshodata in the example in this guide) SHOAZUREKEY The private key for the storage service The following are optional, and are needed if you wish to do basic administration (changing the number of active instances) from the Sho console instead of the Azure web portal:
SHOAZUREHOST The name of the hosting account SHOAZUREDEPLOYSLOT The deployment slot you used for the Sho worker roles (either “staging” or “deployment”) SHOAZURECERTNAME The name of the certificate you created (e.g., “Windows Azure Authentication Certificate”) SHOAZURESUBID The subscription ID for your Azure subscription. This can be found on the Windows Azure portal screen. Usage
Here is a brief example of how to use the package so you can test your installation. Please read the user guide for more complete information.
>>> paramsweep.addDemoDir()
>>> import paramsweeptest
>>> session = paramsweep.run(paramsweeptest.add, 100, [1,2,3,4,5])
The runsweep function returns a parameter sweep session object:
>>> print session
ParamSweepSession('2c574185-9cd3-4ba1-a6f3-9668424374a8')The session runs asynchronously on the cloud. We can check to see if it’s finished by calling isDone(). If it is, we can call getResults to get the results from each of the jobs. Alternately we can call waitResults(), which blocks until it finishes, and then return the result values.
>>> print session.isDone()
True
>>> print session.getResults()
[101, 102, 103, 104, 105]
It’s a good idea to delete the server-side data associated with this session when you’re done.
>>> session.cleanup()
Service utilities
The Sho Azure package includes a function that allows you to change the number of Azure worker role instances that are running in the cloud, waiting for jobs. If you want to use this function instead of using the web portal, you’ll have to add a certificate to your service.
First, you’ll need to generate a new self-signed certificate in a .cer file. The following blog post describes one way to do this:
If you are more comfortable with the command line, another method is described here:
To add the certificate to your Azure subscription, select “Management Certificates” in the sidebar and then click the “Add Certificate button”

Then, click the Browse button in the dialog box and find your .cer file:

Using the API from Sho
In order to change the number of deployment instances, you can call the changeNumWorkerRoles() function:
>>> req = azureservice.changeNumWorkerRoles(num)
This function returns a request ID, which you can use to check on the status of the operation. It typically takes several minutes or so to change the number of instances.
>>> azureservice.getOperationStatus(req)
Setup Summary
To use the parameter sweep facilities for running jobs in the cloud, your users will need to set the following environment variables on the client computers:
SHOAZUREACCOUNT The name of the storage account you created (myshodata in the example in this guide) SHOAZUREKEY The private key for the storage service For using the Sho service utilities described in this document, you will also need to set the following environment variables:
SHOAZUREHOST The name of the hosting account SHOAZUREDEPLOYSLOT The deployment slot you used for the Sho worker roles (either “staging” or “deployment”) SHOAZURECERTNAME The name of the certificate you created (e.g., “Windows Azure Authentication Certificate”) SHOAZURESUBID The subscription ID for your Azure subscription. This can be found on the Windows Azure portal screen. Thanks! And please send feedback to shofeedback@microsoft.com
-
Sho External API Guide
If you’d like to use the Sho libraries directly from .NET (C#, Managed C++, F#, etc.), you’ll need to add references to specific libraries depending on what functionality you wish to use; in some cases you’ll also need to do a bit of setup so that the references will resolve properly. This guide explains how to do this.
Installing the Libraries
To get the libraries, we recommend installing Sho so that you can use the Sho Console as well; however, to build against the libraries, all you need are the contents of the “bin” directory from the Sho install; you can get these by copying them from your Sho install (evaluate “shobindir” in the Sho console to find the location). Thus, if you’re putting code into source control, distributing the code, etc., you’ll only need to distribute the bin directory. Note that if you plan to use EmbeddedSho, you’ll likely want to copy the entire Sho directory, as you’ll need to point to it when creating an EmbeddedSho engine.
Code Setup
Because the ShoArray classes contain both managed and unmanaged code to achieve maximal computation speed, the array libraries depend on some satellite DLLs. In order for the managed libraries to resolve these references, you’ll have to do one of the following:
- [preferred method] Set the environment variable SHODIR to the parent of Sho’s bin directory. Alternatively, you can set the variable SHOBINDIR to the bin directory directly. For instance, if you copied the bin directory from the Sho install to C:librariesShobin, you should point SHODIR to C:librariesSho. Note that you can set the variable programatically (ideally as soon as the app starts) viaSystem.Environment.SetEnvironmentVariable(“SHODIR”,…)
- Another option is to put your .exe into the Shobin directory, or equivalently copy the Shobin directory to the directory that contains your .exe.
What References Do I Need to Add?
The table below lists the DLL’s and namespaces required for various aspects of Sho functionality.
Functionality Namespaces Referenced DLLs Basic matrix math ShoNS.Array ShoArray.dllMatrixInterf.dll Basic matrix + complex numbers ShoNS.ArrayMicrosoft.Scripting.Math ShoArray.dllMatrixInterf.dllMicrosoft.Dynamic.dll Extensions for Python matrix code ShoNS.ArrayShoNS.PythonExtensions ShoArray.dllMatrixInterf.dllPythonExt.dll Random number generation ShoNS.MathFunc Rand.dll Auto-mapping functions ShoNS.ArrayShoNS.MathFunc ShoArray.dllMatrixInterf.dllMathFunc.dll Reading/writing delimited files ShoNS.Array
ShoNS.IO
ShoArray.dllMatrixInterf.dlldlmIO.dll Plotting/charting and other visualization ShoNS.Visualization ShoViz.dllSystem.Windows.Forms Serialization of objects (including Python objects) ShoNS.PicklingSystem.IO ShoPickleHelper.dll Embedding a Sho interpreter in your C# code ShoNS.Hosting EmbeddedSho.dllIronPython.dllIronPython.Modules.dll Sample Projects
The following projects show examples of how to use the Sho libraries from C#. Each zip file contains a Visual Studio solution file; you should unzip this to {SHODIR}playpen so that the relative references will work properly.
- CSharpExample – shows how to create an array, do some linear algebra operations, and create a plot window from C#.[Project Zip file]
- EmbeddedShoTest – shows how to create an EmbeddedSho engine, pass variable values back and from C# to Sho, and execute Sho statements (including a plot).][Project Zip file]
Contact
People
Sumit Basu
Senior Principal Researcher