Video has become ubiquitous on the Internet, broadcasting channels, as well as that captured by personal devices. This has encouraged the development of advanced techniques to analyze the semantic video content for a wide variety of applications, such as video representation learning [CVPR 2017], video highlight detection [CVPR 2016], video summarization, object detection, action recognition [CVPR 2016, ICMR 2016], semantic segmentation, and so on.
Highlight detection
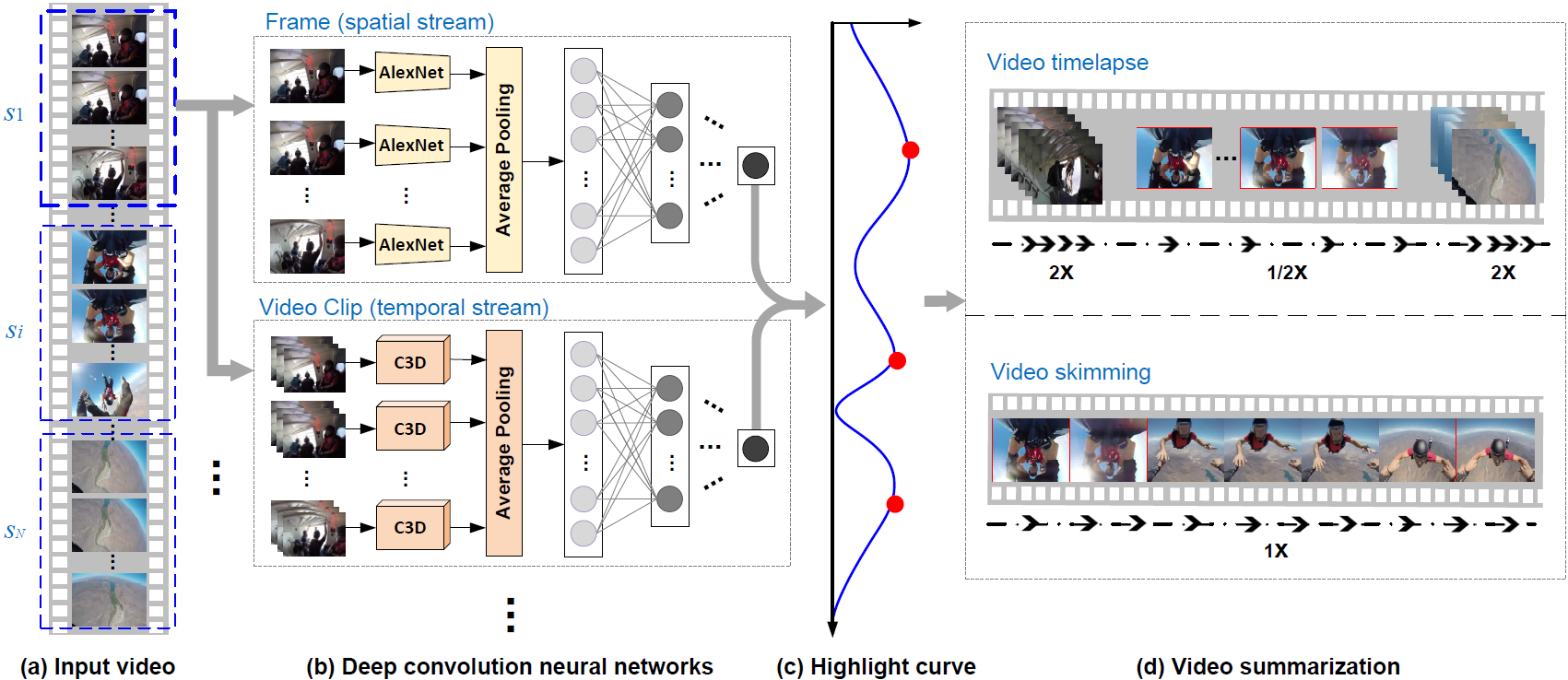
The emergence of wearable devices such as portable cameras and smart glasses makes it possible to record life logging first-person videos. Browsing such long unstructured videos is time-consuming and tedious. We study the discovery of moments of user’s major or special interest (i.e., highlights) in a video, for generating the summarization of first-person videos. Specifically, we propose a novel pairwise deep ranking model that employs deep learning techniques to learn the relationship between highlight and non-highlight video segments. A two-stream network structure by representing video segments from complementary information on appearance of video frames and temporal dynamics across frames is developed for video highlight detection. Given a long personal video, equipped with the highlight detection model, a highlight score is assigned to each segment. The obtained highlight segments are applied for summarization in two ways: video timelapse and video skimming. The former plays the highlight (non-highlight) segments at low (high) speed rates, while the latter assembles the sequence of segments with the highest scores.
Action recognition
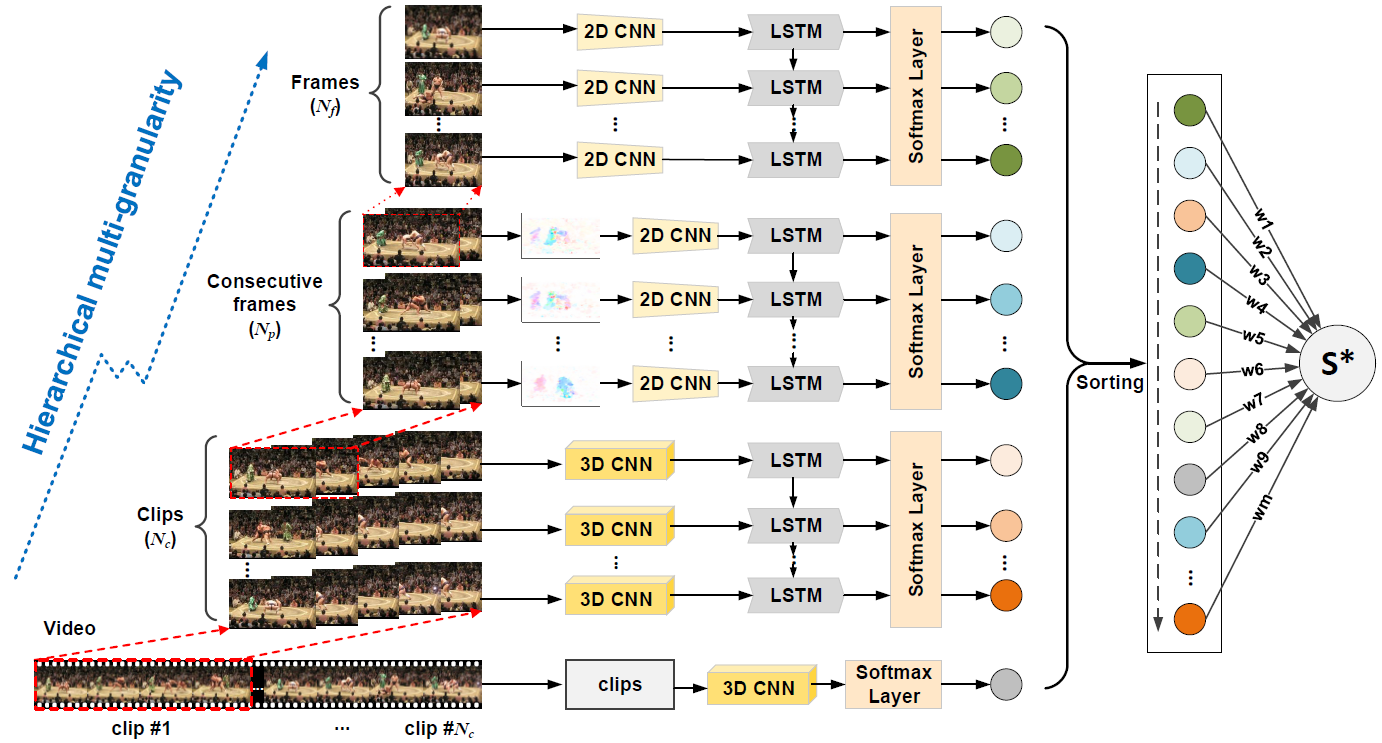
Recognizing actions in videos is a challenging task as video is an information-intensive media with complex variations. Most existing methods have treated video as a at data sequence while ignoring the intrinsic hierarchical structure of the video content. In particular, an action may span different granularities in this hierarchy including, from small to large, a single frame, consecutive frames (motion), a short clip, and the entire video. We present a novel framework to boost action recognition by learning a deep spatio-temporal video representation at hierarchical multi-granularity.