
Automatically describing visual content with natural language is a fundamental challenge of computer vision and multimedia. Sequence learning (e.g., Recurrent Neural Networks), attention mechanism, memory networks, etc., have attracted increasing attention on visual interpretation. In this project, we are focusing on the following topics related to the emerging topic of “vision and language”:
- Image and video captioning, including MSR-VTT video to language grand challenge and datasets (http://ms-multimedia-challenge.com/ (opens in new tab)).
- Image and video commenting (conversation)
- Visual storytelling (e.g., generation of paragraph and poem)
- Visual question-answering (VQA)
In our paper published in CVPR 2016, we present a novel unified framework, named Long Short-Term Memory with visual-semantic Embedding (LSTM-E), which can simultaneously explore the learning of LSTM and visual-semantic embedding. In our paper accepted to CVPR 2017, we propose to incorporate copying mechanism in image captioning for learning novel objects. We also present the Long Short-Term Memory with Transferred Semantic Attributes (LSTM-TSA) — a novel deep architecture that incorporates the transferred semantic attributes learnt from images and videos into the CNN plus RNN framework, by training them in an end-to-end manner. For visual question-answering, in our work accepted to CVPR 2017, we propose a multi-level joint attention network (MLAN) for visual question answering that can simultaneously reduce semantic gap by semantic attention and benefit fine-grained spatial inference by visual attention.
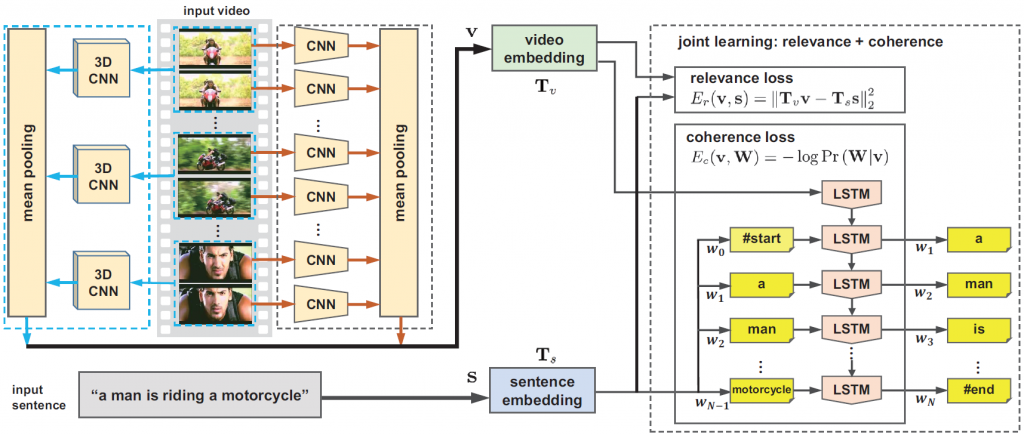
Figure. LSTM-E [Pan et al., CVPR’16]
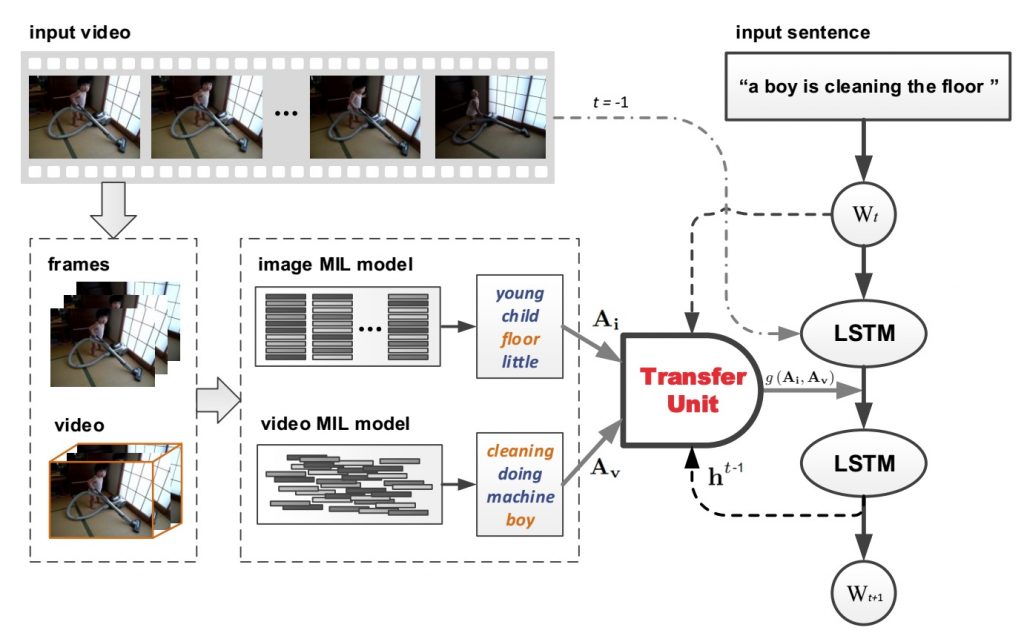
Figure of LSTM-TSA [Pan et al., CVPR’17]
Microsoft Research Video to Language Grand Challenge (http://ms-multimedia-challenge.com/ (opens in new tab))
Video has become ubiquitous on the Internet, broadcasting channels, as well as personal devices. This has encouraged the development of advanced techniques to analyze the semantic video content for a wide variety of applications. Recognition of videos has been a fundamental challenge of computer vision for decades. Previous research has predominantly focused on recognizing videos with a predefined yet very limited set of individual words. In this grand challenge, we go a step further and target for translating video content to a complete and natural sentence. Given an input video clip, the goal is to automatically generate a complete and natural sentence to describe video content, ideally encapsulating its most informative dynamics.
People
Jianlong Fu
Principal Research Manager
Bei Liu
Senior Researcher