
Netco: Cache and I/O Management for Analytics over Disaggregated Stores
- Virajith Jalaparti ,
- Chris Douglas ,
- Mainak Ghosh ,
- Ashvin Agrawal ,
- Avrilia Floratou ,
- Srikanth Kandula ,
- Ishai Menache ,
- Joseph (Seffi) Naor ,
- Sriram Rao
ACM Symposium on Cloud Computing (SOCC) |
Best Paper Award
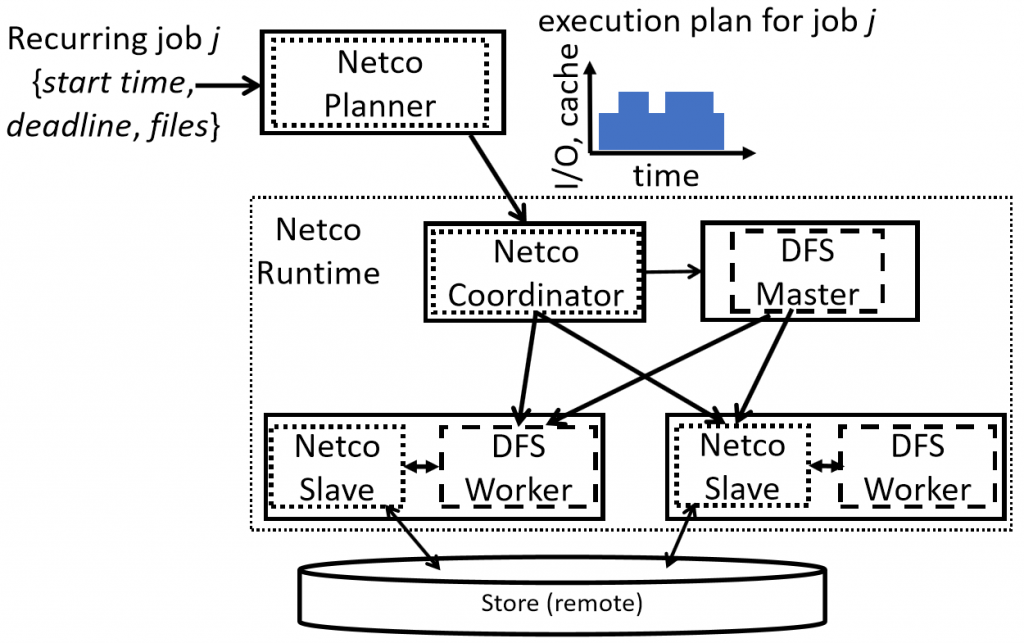
We consider a common setting where storage is disaggregated from the compute in data-parallel systems. Colocating caching tiers with the compute machines can reduce load on the interconnect but doing so leads to new resource management challenges. We design a system, Netco, which prefetches data into the cache (based on workload predictability), and appropriately divides the storage and network bandwidth between the prefetches and serving ongoing jobs. Netco makes various decisions (what content to cache, when to cache and how to apportion bandwidth) to support end-to-end optimization goals such as maximizing the number of jobs that meet their service-level objectives (e.g., deadlines). Our implementation of these ideas is available within the open-source Apache HDFS project. Experiments on a public cloud, with production-trace inspired workloads, show that Netco uses up to 5x less remote I/O compared to existing techniques and increases the number of jobs that meet their deadlines up to 80%.