

Generative models are an important subset of machine learning goals and tasks that require realistic and statistically accurate generation of target data. Among all available generative models, generative adversarial networks (GANs) have emerged recently as a leading and state-of-the-art method, particularly in image generation tasks. While highly successful with continuous data, generation of discrete data with GANs remains a challenging problem that limits its applications in language and other important domains. In this post, we present our work on boundary-seeking GANs done in collaboration with Adam Trischler, Gerry Che, Kyunghyun Cho (opens in new tab) and Yoshua Bengio (opens in new tab) – a principled method for training GANs on discrete data that was accepted to the International Conference for Learning Representations (ICLR 2018).
Generative models
A generative model is a method for generating a target distribution with the desired statistics. Generative models are a fundamental facet of machine learning, instrumental to a number of important tasks such as:
- Conditional generation (for example, text-to-image, image captioning, machine translation)
- Style/domain transfer
- Denoising/inpainting
- Super-resolution
- Speech synthesis
- And many more
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the latest episodes on demand.
As an illustrative example, suppose we have a generative process that takes an input variable (such as noise) that it transforms through some set of tuning parameters, θ. For this process we are not only interested in the quality of the output, but the cumulative statistics (for example, frequencies of color, shape, and so on). In general, the generative process induces a probability distribution, Qθ, that is a function of some input distribution Qz (often called a prior, that can be over noise but also known variables), and the parameters of the generation machine, Gθ. See Figure 1.
The goal is to have the induced distribution, Qθ, match a target distribution, P (both in quality and frequencies). For learning, optimization commonly amounts to minimizing a difference measure between the induced and a target distribution. Arguably, the most common difference measures used in generative models come from the family of f-divergences, such as the KL-divergence, though other measures such as integral probability metrics (IPMs) have been studied extensively.
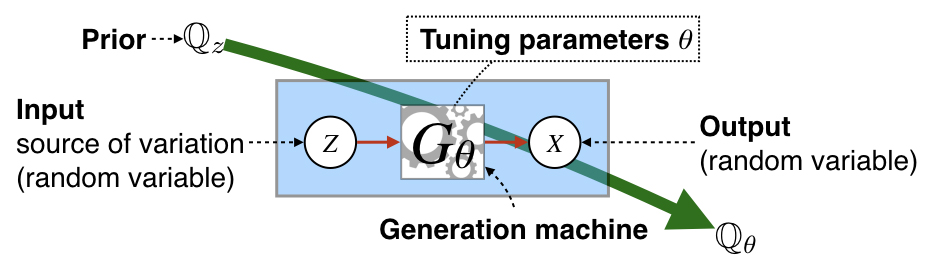
Figure 1. Fundamentals of generative models.
Generative adversarial networks (GANs)
Recently, many of the applications mentioned above have achieved state-of-the-art with generative adversarial networks (GANs). GANs represent a new and unique approach relative to previous methods and are characterized by the use a classifier to estimate a measure of probabilistic difference.
The basic setup follows an adversarial two-player game. The classifier, often called the discriminator or critic maximizes a lower-bound of a difference measure (such as the JSD or Wasserstein distance), while the generator minimizes the quantity estimated by the discriminator (in other words, tries to “fool” the discriminator). With continuous data, the pathway from noise, z, to the discriminator output is a completely differentiable function nearly everywhere, so both discriminator and generator can be trained using back-propagation. See Figure 2.
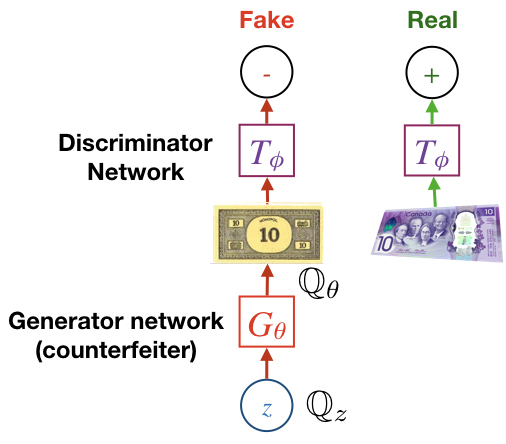
Figure 2. Generated Adversarial Networks (GAN).
While GANs have achieved state-of-the-art in many machine learning tasks, there is a major drawback to using GANs for generating discrete data. This is because the discrete generation process has zero gradient nearly everywhere (and is otherwise infinite), so it is not possible to use back-propagation alone to train the generator. Back-prop through discrete processes is a difficult and unsolved problem, and many proposed solutions, such as the Gumbel softmax trick, have been applied in a variety of domains. However, our work was motivated in-part by a lack of successful solutions with GANs. Our approach, which we call boundary-seeking GANs (BGANs), is presented here.
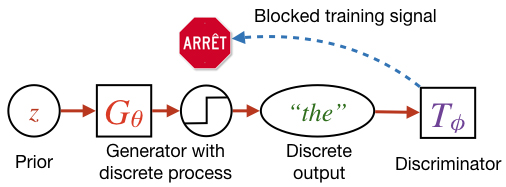
Figure 3. Discrete generation with GANs.
Why discrete generation with GANs?
Discrete generation is a necessary for performing many machine learning tasks, many of which are in natural language processing, such as machine translation and caption generation. However, discrete generation can be found in a wide variety of domains, such as semantic segmentation of images and genetics.
Traditionally, language generation such as machine translation is done using maximum likelihood estimation (MLE) with autoregressive models, such as recurrent neural networks (RNNs). This approach is convenient because it formulates learning as a conditional next-step generation task. However, the standard versions of these approaches train generators that tend to stay close to the training data, which motivates a number of fixes.
Hypothetically, generative adversarial networks should not be as susceptible to this sort of overfitting, as the gradients used to train the generator are not directly derived from specific training examples. Rather, the generator receives its training signal from the discriminator given generated samples.
Boundary-seeking GANs
In order to train the generator of discrete data, we formulate a policy gradient based on the likelihood ratio as estimated by the discriminator. For f-GANs, when the discriminator is optimal, we can write the target density as:

where f* is the convex conjugate to f-divergence function, p and qθ are real and generated probability densities, and T* is the optimal discriminator. The optimal discriminator is not normally available to us; however, we can reasonably estimate the true density by evaluating the above equation at a sub-optimal discriminator. From this estimate, we can construct a policy gradient for the generator based on either the KL or the reversed KL divergences. In our case, we model the generative processes as sampling from a multinomial Bernoulli distribution whose means are determined by a deep neural network. The gradient of the generator loss, which resembles importance sampling, can be computed as a policy gradient:

This gradient then can be used to train a generator of discrete data without relying on back-prop through the generative process. See Figure 3.
Discrete generation
For discrete generation, we tested our approach on the MNIST dataset, as well as a quantized version of the popular CelebA dataset.
Figure 4 shows randomly selected samples from our model trained on MNIST. Figure 5 shows samples from the quantized CelebA dataset and figure 6. shows generated samples from our model trained on quantized CelebA.
MNIST results also quantitatively outperform a well-known competing method, WGAN-GP, that uses a form of continuous relaxation to circumvent the discrete process.
We also tested our model on language generation with the 1-Billion Word dataset. Rather than using an autoregressive model, we performed character-level generation using a CNN, generating sequences of 64 characters.
- What was like one of the July 2
- College is out in contesting rev
- Thene says the sounded Sunday in
- The BBC nothing overton and slea
While generation is not as good as MLE-based methods using RNNs, our model was able to learn how to separate and spell most words correctly as well as learn some basic grammar. Future work will focus on how to incorporate sequential generation using our method to improve generation.

Figure 4. Generated MNIST digits.

Figure 5. Generated quantized CelebA faces.

Figure 6. Ground truth samples from quantized CelebA.
Continuous generation
While GAN generation of continuous data can be trained via back-prop, the generator loss is a concave function, relying on constantly optimizing the discriminator to stabilize learning. However, we can borrow from some of the ideas behind our discrete approach to develop a convex function, which essentially trains the generator to aim for the decision boundary of the discriminator.

Figure 7. Generated CelebA faces.

Figure 8. Generated LSUN bedrooms.

Figure 9. Imagenet generated images.
Our results show improved stability for GAN training for the generator, as well as impressive generation on a variety of datasets with the help of discriminator regularization, including on unconditional Imagenet generation (see Figures 7, 8 and 9.)
We believe that boundary-seeking GANs are an important step toward state-of-the-art generation of discrete data such as natural language and provide further stabilization of GANs of continuous data.
