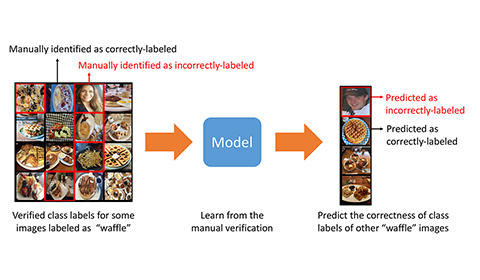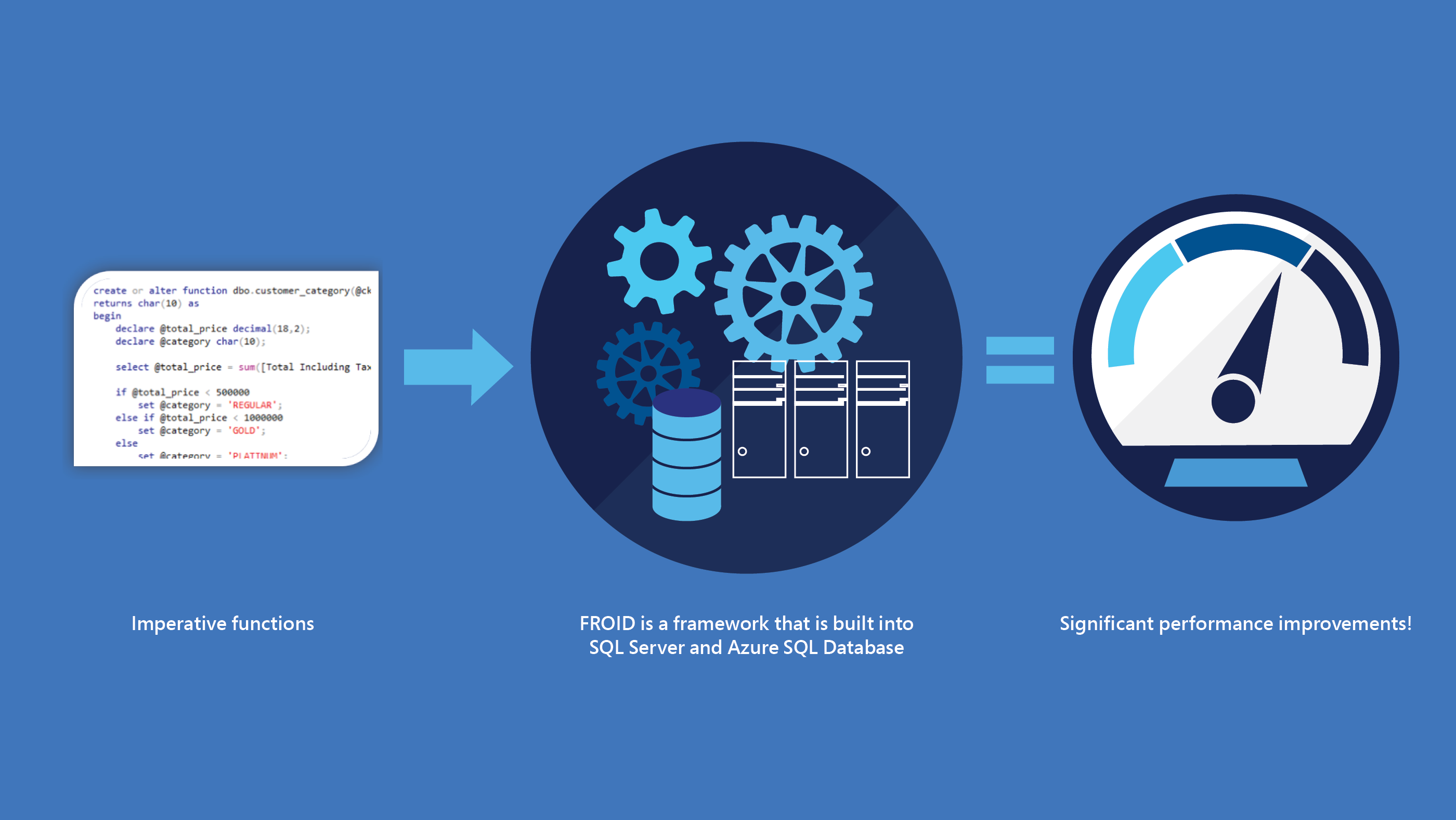
Optimizing imperative functions in relational databases with Froid
August 27, 2018 | Karthik Ramachandra
For decades, databases have supported declarative SQL as well as imperative functions and procedures as ways for users to express data processing tasks. While the evaluation of declarative SQL has received a lot of attention resulting in highly sophisticated techniques, improvements in the efficient evaluation…