
Finding and fixing bugs in code is a time-consuming, and often frustrating, part of everyday work for software developers. Can deep learning address this problem and help developers deliver better software, faster? In a new paper, Self-Supervised Bug Detection and Repair, presented at the 2021 Conference on Neural Information Processing Systems (NeurIPS 2021), we show a promising deep learning model, which we call BugLab. BugLab can be taught to detect and fix bugs, without using labelled data, through a “hide and seek” game.
To find and fix bugs in code requires not only reasoning over the code’s structure but also understanding ambiguous natural language hints that software developers leave in code comments, variable names, and more. For example, the code snippet below fixes a bug in an open-source project in GitHub.

Here the developer’s intent is clear through the natural language comment as well as the high-level structure of the code. However, a bug slipped through, and the wrong comparison operator was used. Our deep learning model was able to correctly identify this bug and alert the developer.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the latest episodes on demand.
Similarly, in an another open-source project, the code (below) incorrectly checked if the variable write_partitions is empty instead of the correct variable read_partition.

The goal of our work is to develop better AI that can automatically find and repair bugs like the two shown above, which seem simple, but are often hard to find. Freeing developers from this task gives them more time to work on the more critical (and interesting) elements of software development. However, finding bugs – even seemingly small ones – is challenging, as a piece of code typically does not come with a formal specification of its intended behavior. Training machines to automatically recognize bugs is further complicated by a lack of training data. While vast amounts of program source code are available through sites such as GitHub, only a few small datasets of explicitly annotated bugs exist.
To tackle this problem, we propose BugLab, which uses two competing models that learn by playing a “hide and seek” game that is broadly inspired by generative adversarial networks (GAN). Given some existing code, presumed to be correct, a bug selector model decides if it should introduce a bug, where to introduce it, and its exact form (e.g., replace a specific “+” with a “-“). Given the selector choice, the code is edited to introduce the bug. Then, another model, the bug detector, tries to determine if a bug was introduced in the code, and if so, locate it, and fix it.
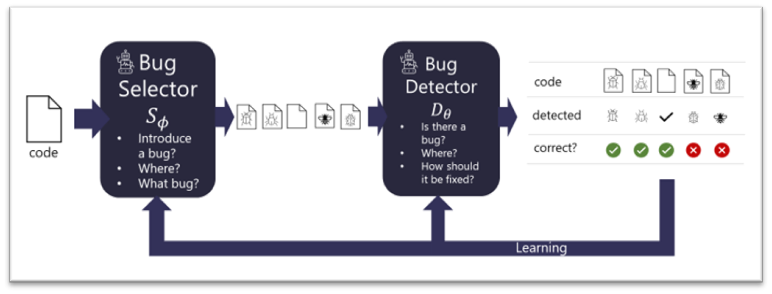
These two models are jointly trained without labeled data, i.e., in a self-supervised way, over millions of code snippets. The bug selector tries to learn to “hide” interesting bugs within each code snippet and the detector aims to beat the selector by finding and fixing them. Through this process, the detector becomes increasingly capable of detecting and fixing bugs, while the bug selector learns to generate increasingly challenging training examples.
This training process is conceptually similar to GANs. However, our bug selector does not generate a new code snippet from scratch, but instead rewrites an existing piece of code (assumed to be correct). In addition, code rewrites are – necessarily – discrete and gradients cannot be propagated from the detector to the selector. Note that in contrast to GANs, we are interested in obtaining a good detector (akin to a GAN’s discriminator), rather than a good selector (akin to a GAN’s generator). Alternatively, the “hide and seek” game can be seen as a teacher-student model, where the selector tries to “teach” the detector to robustly locate and fix bugs.
Results
In theory, we could apply the hide-and-seek game broadly, teaching a machine to identify arbitrarily complex bugs. However, such bugs are still outside the reach of modern AI methods. Instead, we are concentrating on a set of commonly appearing bugs. These include incorrect comparisons (e.g., using “<=” instead of “<” or “>”), incorrect Boolean operators (e.g., using “and” instead of “or” and vice versa), variable misuses (e.g., incorrectly using “i” instead of “j”) and a few others. To test our system, we focus on Python code.
Once our detector is trained, we use it to detect and repair bugs in real-life code. To measure performance, we manually annotate a small dataset of bugs from packages in the Python Package Index (opens in new tab) with such bugs and show that models trained with our “hide-and-seek” method are up to 30% better compared to other alternatives, e.g., detectors trained with randomly inserted bugs. The results are promising, showing that about 26% of bugs can be found and fixed automatically. Among the bugs our detector found were 19 previously unknown bugs in real-life open-source GitHub code. However, the results also showed many false positive warnings, suggesting that further advancements are needed before such models can be practically deployed.
How machine learning “understands” code
We now dive a bit deeper into our detector and selector models. How can deep learning models “understand” what a snippet of code is doing? Past research (opens in new tab) has shown that representing code as a sequence of tokens (roughly “words” of code) yields suboptimal results. Instead, we need to exploit the rich structure of the code, including its syntax, data, and control flow. To achieve this, inspired by our earlier work, we represent entities within the code (syntax nodes, expressions, identifiers, symbols, etc.) as nodes in a graph and indicate their relationships with edges.
Given such a representation, we can use a number of standard neural network architectures to train bug detectors and selectors. In practice, we experimented with both graph neural networks (GNNs) and relational transformers. Both these architectures can leverage the rich structure of the graph and learn to reason over the entities and their relations. In our paper, we compare the two different model architectures and find that GNNs in general outperform relational transformers.
Conclusions
Creating deep learning models that learn to detect and repair bugs is a fundamental task in AI research, as a solution requires human-level understanding of program code and contextual cues from variable names and comments. In our BugLab work, we show that by jointly training two models to play a hide-and-seek game, we can teach computers to be promising bug detectors, although much more work is needed to make such detectors reliable for practical use.
Related Links
- NeurIPS 2021 paper, “Self-Supervised Bug Detection and Repair”.
- The PyPIBugs dataset