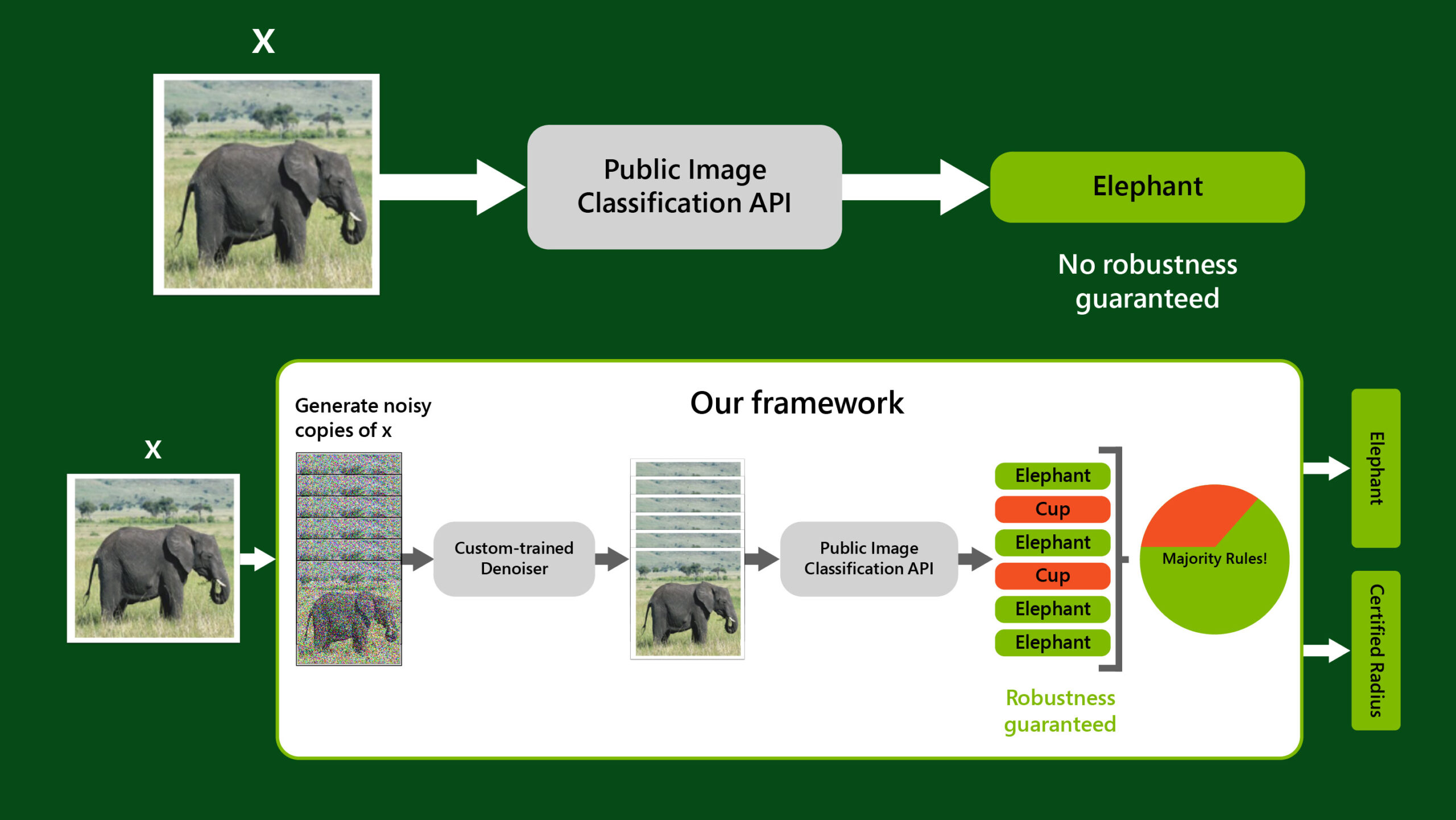
Factorized layers revisited: Compressing deep networks without playing the lottery
From BiT (928 million parameters (opens in new tab)) to GPT-3 (175 billion parameters (opens in new tab)), state-of-the-art machine learning models are rapidly growing in size. With the greater expressivity and easier trainability of these models come skyrocketing training costs, deployment difficulties, and even…