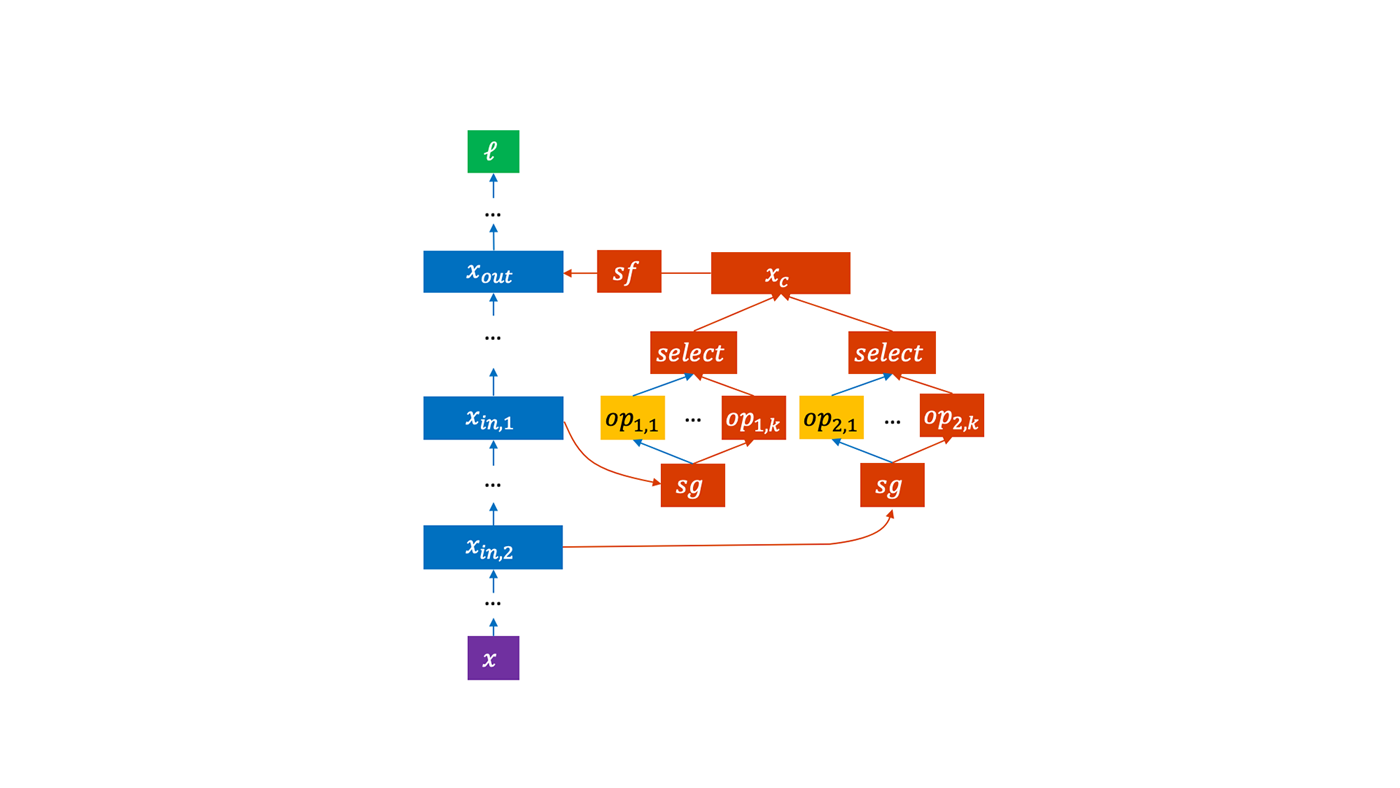
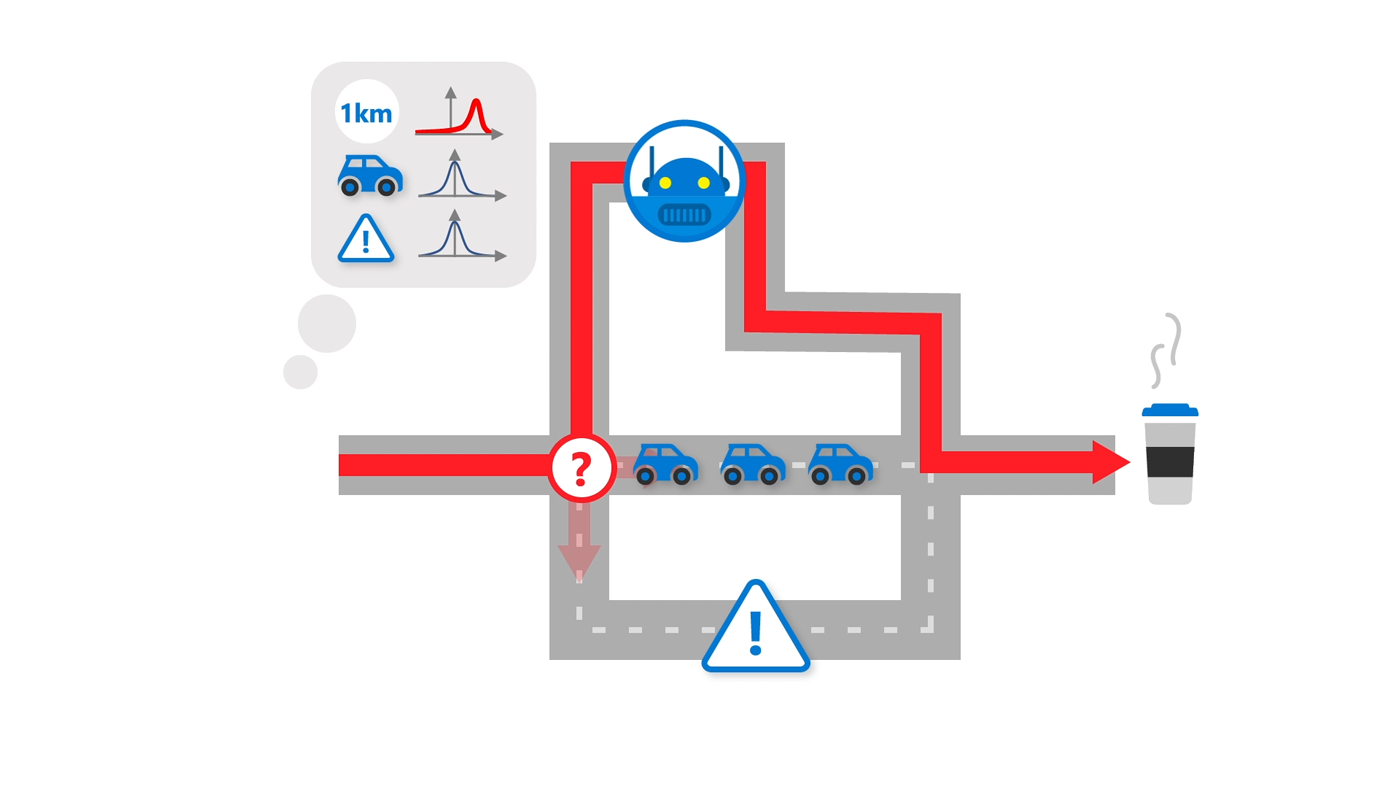
Next-generation architectures bridge gap between neural and symbolic representations with neural symbols
December 12, 2019 | Paul Smolensky
In both language and mathematics, symbols and their mutual relationships play a central role. The equation x = 1/y asserts the symbols x and y—that is, what they stand for—are related reciprocally; Kim saw the movie asserts that Kim and the movie are perceiver and…