

Project Everest (opens in new tab) is a multiyear collaborative effort focused on building a verified, secure communications stack designed to improve the security of HTTPS, a key internet safeguard. This post—about the proving methodology and verification tools of Project Everest—is the third in a series exploring the groundbreaking work, which is available on GitHub (opens in new tab) now.
Building, deploying, and maintaining software at scale is a large engineering effort, and when that software is intertwined with machine-checked proofs of correctness, the engineering involved is largely without precedent. In Project Everest (opens in new tab), dozens of researchers and engineers push to five open-source GitHub repositories, building about 600,000 lines of code and proofs, continuously integrated using Azure DevOps, hundreds of times every day. There have been countless hard-won lessons on software and proof-engineering best practices, ranging from developing and maintaining robust proofs in the face of an evolving codebase to tweaking the format of our compilers to enable humans to audit the C and assembly-language code produced by our software verification toolchain.
video series

On Second Thought
A video series with Sinead Bovell built around the questions everyone’s asking about AI. With expert voices from across Microsoft, we break down the tension and promise of this rapidly changing technology, exploring what’s evolving and what’s possible.
But this post isn’t about the engineering. It’s about the science that underlies it—the science of program proof. I mean proving deep theorems about programs, proofs that establish that the full semantics of a program adhere to a mathematical model of all its behaviors, not just theorems proving, say, the absence of specific kinds of bugs (which is, of course, also useful!).
From the early days of computer science, the potential of program proof to eradicate large classes of software errors has been widely recognized; however, until recently, few practical applications were feasible. The proof techniques were difficult to apply to full-fledged programming languages, and proofs were hard to scale to large programs. Oftentimes, the proofs that were done came at the cost of other important aspects of software, such as performance. But today, what seemed impossible just a few years ago is becoming a reality. We can, in certain domains, produce fully verified software at a nontrivial scale and with runtime performance that meets or exceeds the best unverified software.
Fast—and verified—secure communication code
Project Everest is a case in point: We produce verified cryptographic routines, parsers, and protocols that are deployed in production settings with strong correctness and security guarantees and great performance. Our recently released EverCrypt cryptographic provider consists of 23,000 lines of verified C code and 18,000 lines of verified assembly code extracted from 107,000 lines of code and proof in the F* programming language and proof assistant—a development effort of roughly three person-years. The chart below shows the throughput of several verified cryptographic routines since 2014. Over the last five years, there’s been slow but steady improvement, but this year, with EverCrypt, we made a noticeable jump to finally verify the fastest assembly code of OpenSSL (opens in new tab) for AES-GCM, a crypto routine used by 90 percent of secure internet connections.
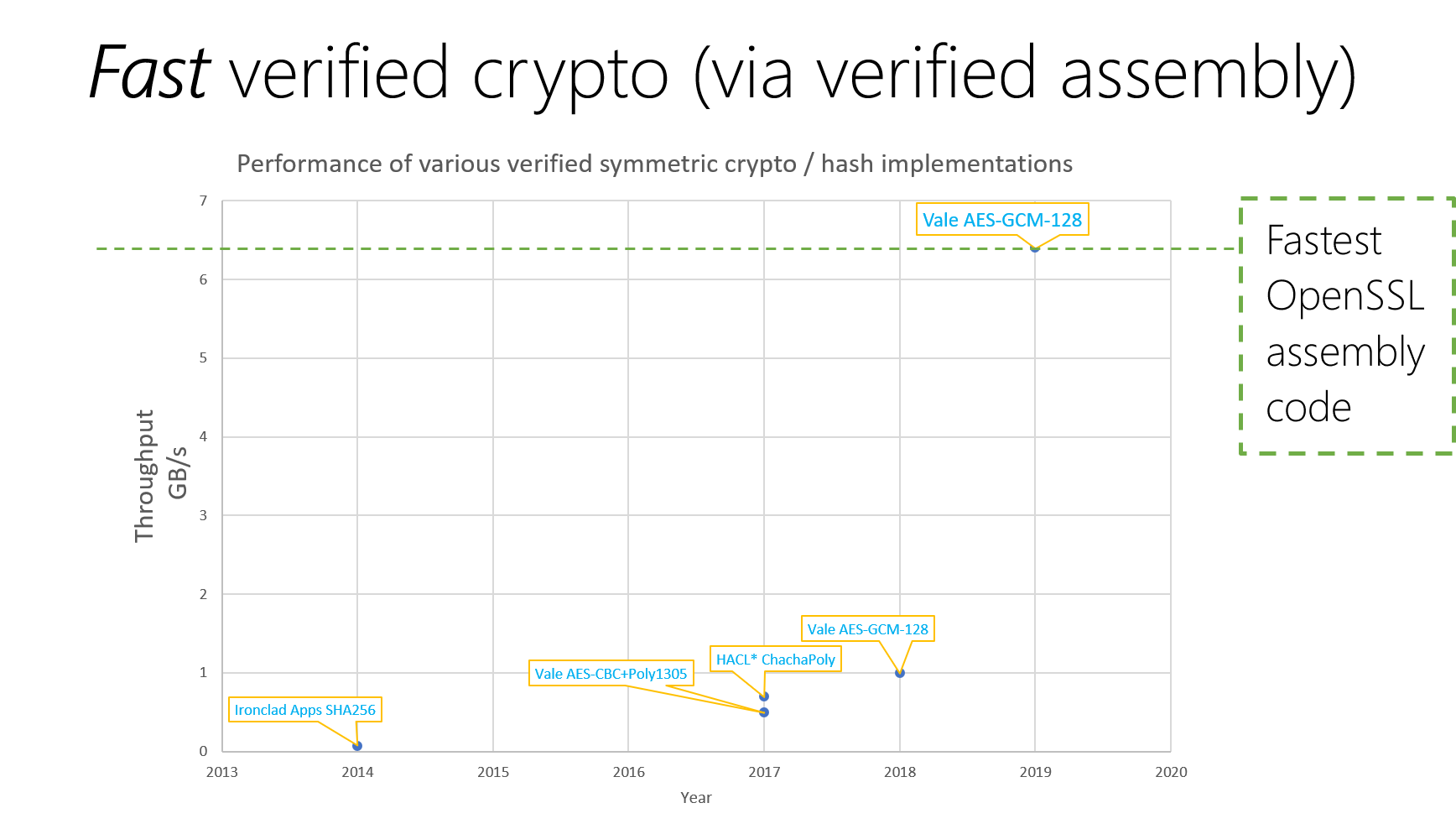
After years of slow but steady gains in the throughput of verified cryptographic routines, Project Everest made significant progress with the verification of the fastest assembly code of OpenSSL for AES-GCM.
What made it possible for verified code to finally catch up to the fastest unverified code out there? Program verification tools and methodologies have passed a tipping point that has allowed large, previously intractable problems to be decomposed effectively and smaller problems to be solved with increasing automation.
A trinity of program proof
 Program verification researchers have long sought a proof methodology and tool to excel in three dimensions that can often be at odds, where maximizing for one diminishes the ability to achieve the highest level of another:
Program verification researchers have long sought a proof methodology and tool to excel in three dimensions that can often be at odds, where maximizing for one diminishes the ability to achieve the highest level of another:
Automation: Proving a large program requires proving thousands or even millions of small theorems. Without automation, the task is hopelessly tedious. Recent advances in SMT solving are well documented—Z3 (opens in new tab), developed by Microsoft Research, is a leading example—and many program verification tools have leveraged these advances to automate vast numbers of simple proofs.
Expressiveness: Proving millions of simple theorems alone doesn’t cut it. At the crux of any significant software verification effort is a genuinely complex proof involving sophisticated mathematics. As such, one needs a full-featured modern language coupled with a powerful logic in which to conduct deep mathematical reasoning. Less widely appreciated than advances in SMT solvers, but no less important, are advances that have led to logics that provide both a theoretical foundation for mathematics as well as a practical foundation for software. A significant milestone was the emergence of large verified software artifacts, notably the CompCert C verified compiler (opens in new tab) in 2006. These advances demonstrated that type theory (opens in new tab), which was originally conceived in the 1970s as a new foundation for logic and mathematics, could also be a viable basis for verified software.
Control: To harness the power of type theory and to combine it with the automation of SMT solvers, advances in metaprogramming have allowed proof engineers to tune automated proofs, diagnose failures, develop new domain-specific decision procedures, and script how their programs are proven, generated, and compiled.
Devising a proof methodology and tool that truly excels on all three dimensions is an ongoing research challenge. But several modern proof assistants, such as Coq (opens in new tab), Lean (opens in new tab), Isabelle (opens in new tab), and Agda (opens in new tab), are beginning to deliver simultaneously on all three fronts. F*, the proving methodology and tool of Project Everest (opens in new tab), is as well.
The F* balancing act
The research agenda of F*, now nearly a decade and about 10 research papers in, is to balance automation, expressiveness, and control within a full-fledged programming language and proof assistant. F* is based on type theory but with SMT solving and metaprogramming as essential elements.
Some of the key challenges that we’ve addressed include the following:
- Effects in type theory: Type theory is a logic of pure functions. No real programming language can be purely functional. One of F*’s main innovations is in encoding effects—state, exceptions, I/O—within type theory. A key concept is the Dijkstra monad, invented and applied in F* in a 2013 paper and refined (opens in new tab) and generalized (opens in new tab) repeatedly (opens in new tab) since then. Dijkstra monads give a semantics to effects within type theory using predicate transformers in the style of Dijkstra’s weakest preconditions.
- SMT integration: At the very heart of F* is an encoding of type theory into the logic of an SMT solver. While SMT solvers can’t automate all proofs in type theory (far from it!), they’re remarkably effective at proving a large number of the kinds of goals that arise in a typical program proof. A single complete build of Project Everest’s code produces nearly a million proofs that are dispatched by the Z3 SMT solver.
- Metaprogramming: Building on ideas from Microsoft Research’s Lean theorem prover, Meta-F* (opens in new tab)—a metaprogramming framework—makes F* its own metaprogramming language. It provides Everest proof engineers with the control to construct and inspect proofs and programs programmatically. Meta-F* is at the leading edge of F*, and it continues to evolve and be used in new ways.
- Embedded domain-specific languages: Rather than program and prove directly in type theory, we’ve designed new domain-specific languages (DSLs) within F* and use them to develop precise models and effective automation for specific tasks. We have DSLs embedded in F* for C-like programming; for verified assembly language (opens in new tab) (with which we finally cracked the AES-GCM verification challenge); and even for low-level parsers and serializers, which can produce verified code that can be, in some cases, orders of magnitude faster than existing unverified handwritten code.
Advances in the programming language and verification technology have proven crucial to our work while also providing new insights into application areas. Project Everest’s focus on verified cryptographic communication protocols has generated techniques for doing cryptographic correctness and security proofs on executable implementations of complex algorithms, constructions, protocols (opens in new tab), and even cryptographic providers (opens in new tab), relating low-level optimized implementations to high-level mathematical and security properties.
Looking ahead: Program proof at scale
We finally have methods to build and deploy verified performant secure communication code, but more research is needed to broaden the reach of program proof.
- Making proofs easier: We can verify real code, but it’s still hard work for a committed team of experts. There are many directions to pursue for improving automation; new fragments of logics to consider with different tradeoffs between automation and expressiveness; new program logics for specific kinds of proofs to explore; and more control to achieve to move seamlessly between SMT and tactic-based proofs.
- Handling richer programming features: Logics to reason about concurrency, distribution, asynchrony, probabilities, and the like are still heavily active topics of research in the programming language community. Yes, these concepts can be modeled in type theory; the foundations don’t shift. But what are the right proof methods to use for these important features in real-world code? We’re actively working on that, including adapting separation logic (opens in new tab) for use in F* for proofs about concurrency and developing logical relations for probabilistic program equivalences.
Cryptographic software is a sweet spot for program proof—tricky math, performance-obsessed low-level code, catastrophic bugs—but it’s not the only domain that stands to benefit. Building on our verification tools and methodology, we look to the next set of challenges: verified performant systems code. That includes crucial components of other security- and correctness-critical infrastructure, such as the virtualization technology used in Microsoft Azure. We’ve got our work cut out for us, but building secure and performant low-level code is not so daunting when proofs have your back.



