
Many of our online activities, from receiving and sending emails to searching for information to streaming movies, are driven behind the scenes by cloud-based distributed architectures. Writing concurrent software—programs with multiple logical threads of execution—is of paramount importance to scale to these growing computing needs. Unfortunately, writing correct concurrent software is challenging. Unit, integration, and even stress testing don’t provide reasonable guarantees about the correctness of a concurrent program. Thus, insidious defects can remain latent in software until the late stages of development, potentially adding cost and stress to already tight timelines designed to help ensure new software is still relevant upon release.
Controlled concurrency testing (CCT), an emerging approach in this space, aims to take over the concurrency in a program so that thread/process interleavings can be directly controlled. Using a variety of strategies, CCT attempts to identify buggy program executions, converting the testing problem into a search problem over the space of all possible program behaviors, which can typically be astronomical in number for concurrent programs.
Under the Coyote project, which has been used to build several mission-critical Microsoft Azure services, we’ve been working on providing effective CCT-based solutions to find complex defects arising from concurrency. Existing state-of-the-art CCT strategies are typically hand-tuned, making it nearly impossible to guarantee that a strategy that worked well in a previous application will work well with your application. This led us to ask an intriguing question: can we use machine learning, with no prior knowledge about an application, to figure out enough semantic details to expose bugs with high probability? We gave this a shot and designed QL. To the best of our knowledge, it’s the first reinforcement learning–based CCT search strategy. Our strategy, even without being taught anything about concurrent programs or interleavings, was able to beat the state-of-the-art human-designed CCT strategies.

Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Coyote is a .NET library and tool designed to help ensure that your code is free of concurrency bugs.
QL was presented at the 2020 Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA) (opens in new tab), where it won the Distinguished Artifact Award, and is available open source for experimentation on GitHub as part of Coyote (opens in new tab).

CCT and the trouble with finding concurrency bugs
The CCT framework (Figure 1) comprises a scheduler—which observes the next state of the concurrent program, such as the value of global variables or the set of inflight messages—and a set of enabled program actions, such as “thread T1 writes to a global variable” or “thread T2 sends a message to T1.” Whenever the program executes an action, it transitions to a new state. The job of the scheduler is to simply select an enabled action from a given state.
Since the search space of program behaviors is often very large, we need effective ways of navigating this space. Schedulers employ search strategies, which identify the next action from a particular state that maximizes the likelihood of the program transitioning to a buggy state, one where some program correctness property is violated. Thus, CCT converts the testing problem into a search problem over the space of all interleavings, looking for buggy executions. As mentioned above, existing search strategies typically use human-tuned heuristics based on previously observed bug patterns, which often can’t provide guarantees that a strategy successful in one application will be as effective in another.
Let us consider an example to illustrate why concurrency bugs can be hard to find. Consensus algorithms, coordinating between multiple concurrently executing nodes to reach an agreement, lie at the heart of many modern distributed systems, and Raft (opens in new tab) is a popular consensus algorithm.
A node in the Raft protocol can assume one of three roles: leader, candidate, or follower. The leader receives client requests and replicates them among the remaining nodes. At any point, one or more candidates can initiate a leader-election round, in which nodes exchange voting messages among themselves. The candidate obtaining the most votes is deemed to be the new leader. Raft maintains an important invariant: there can be at most one leader at a time. Failure of this invariant can result in the system transitioning to a corrupted state and is a serious bug.
Akka Raft 2015 (opens in new tab), an implementation of this protocol, had a tricky bug. Candidate nodes lacked the necessary logic to identify and discard duplicate votes, resulting in a vote getting counted multiple times. Duplicate votes can occur because of delays in the network, with a node timing out for the acknowledgment and voting again. To expose this bug, specific events must occur in a definite order: there needs to be an election round with multiple candidates, a candidate \(A\) must receive the most votes, a follower who voted for candidate \(B\) has to time out and send duplicate votes, the vote counts for \(A\) and \(B\) need to match, and the system must end up with two leaders.
Out of the astronomical number of possible behaviors of Raft, it’s challenging for a testing framework such as CCT to drive the system through this specific one. We turned to RL to make searching that space more effective. Additionally, RL allows for a solution that is customized to the application under test, unlike strategies that are hand-tuned based on other scenarios.
QL: CCT meets Q-learning
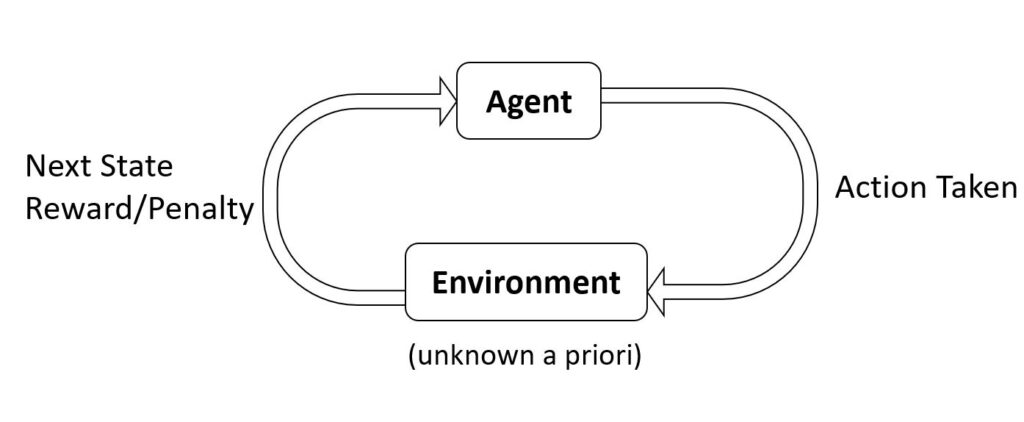
The reinforcement learning (RL) problem (Figure 2) consists of an agent interacting with an environment about which it has no prior knowledge. At each step, the agent chooses an action, which causes the environment to undergo a state transition. In response, the agent observes a new environment state and receives a reward/penalty as feedback for its choice. The agent’s goal is to learn a sequence of actions that maximizes its expected reward. This model has achieved spectacular success in domains such as robotics; game playing, including games like Go and backgammon; and autonomous driving.
A careful look at the CCT and RL architectures reveals some striking similarities. Both have entities (an agent in RL and the search strategy in CCT) that are navigating an unknown search space (the environment in RL and the concurrent program under test in CCT) with a specific objective (maximizing expected reward in RL and maximizing likelihood of finding a concurrency bug in CCT). This was our starting point. We mapped the search strategy component in CCT to an RL agent and the concurrent program under test to the unknown environment.
Our resulting search strategy leverages the classic Q-learning algorithm (opens in new tab) from the RL domain. For each state s and for each action a enabled from that state, QL maintains a quality metric Q(s,a) called the Q-value. QL decides which action to execute next using a Softmax selection function. In response, the program transitions to a new state and presents a penalty signal back to QL, which uses it to adjust the Q-values with the objective of maximizing coverage of the program’s state space.
The key advantage of QL is that instead of focusing on specific bug patterns, you can specify the state space of the program that is relevant to the logic being tested, and QL does the best job of maximizing the coverage of this state space.
Controlled testing of the Raft protocol
We compared QL to two existing state-of-the-art CCT search strategies, Random and probabilistic concurrency testing (PCT). With Raft, Random will, at each step, arbitrarily pick one of the nodes to execute. PCT will assign a set of priorities to all the participating nodes and select the node with the highest priority. It will then sporadically lower the priority of the currently executing node and pass the control to the node that had the second-highest priority. Note that both these strategies are geared toward empirically observed bug patterns.
How can we tell if a strategy is making progress toward uncovering the bug in Raft? Two reasonable metrics include the total number of elected leaders and the total number of election rounds with multiple candidates. A strategy maximizing these metrics is likely to observe more program behaviors in Raft and have a higher likelihood of exposing the bug.
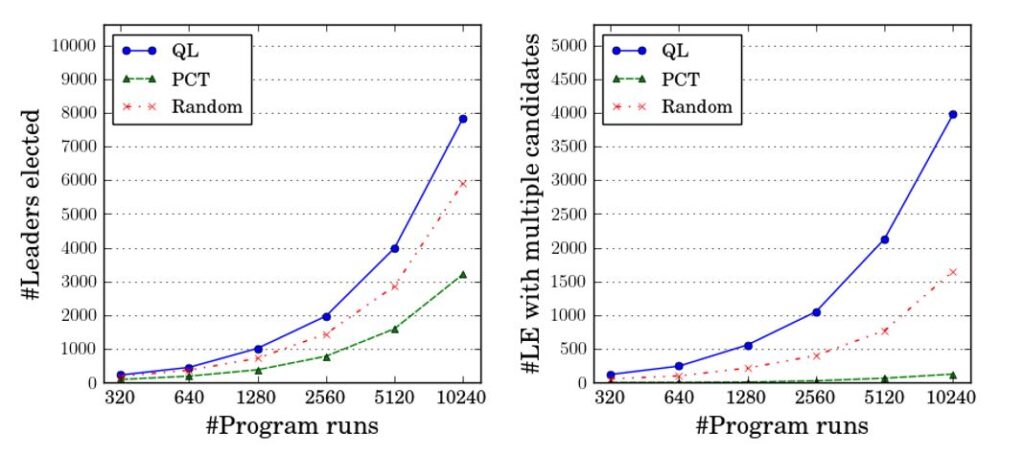
In the above line graphs, the x-axis denotes individual runs of the Raft protocol. The y-axis of the first graph shows the total number of elected leaders explored by the different strategies, and the y-axis of the second graph shows the total number of election rounds in which there are multiple candidates. QL significantly outperforms Random and PCT on both metrics. Does this mean QL is better at finding the Raft bug? You bet! If you invoke a CCT framework 100 times with the different strategies, QL finds the bug 95 times, Random finds it four times, and PCT never finds the bug. We observed this repeatedly, in benchmarks ranging from complex protocols to production Azure services: QL can glean application-specific semantic information during its exploration, allowing it to consistently outperform state-of-the-art CCT strategies.
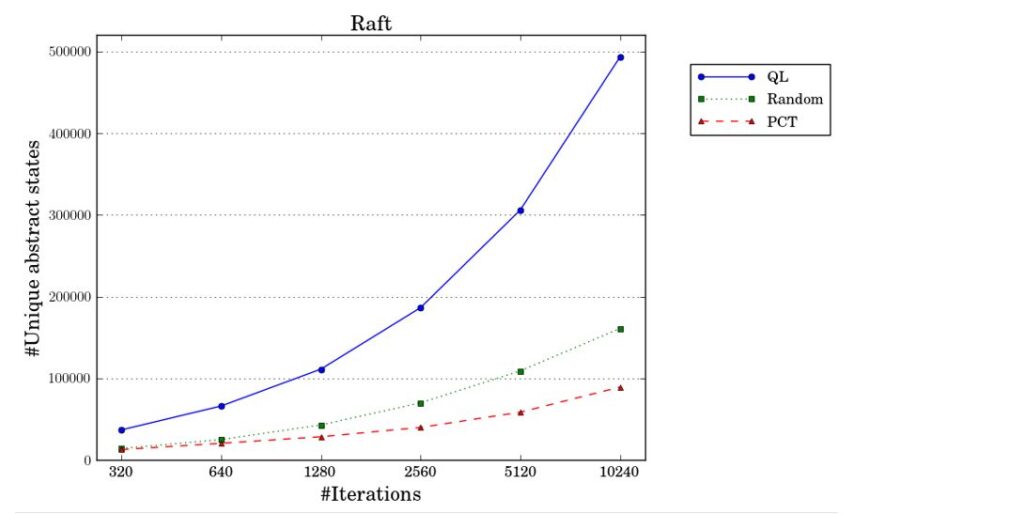
We can gain additional insights into the superior bug-finding ability of QL by comparing its state coverage with Random and PCT. The state of the protocol relevant for testing includes the set of in-flight messages (network state) and the status of each node (its role and whom its voting for currently). Using appropriate APIs, this is the state that we exposed to QL.
As shown in the figure above, in around 10,000 executions of Raft, QL covers nearly three times more states compared with Random and five times more states compared with PCT. The QL strategy is geared toward performing a thorough coverage of the relevant state space, and the superior bug-finding ability is a byproduct.
Find out more
QL is joint work with Microsoft Research Senior Research Software Engineer Pantazis Deligiannis, Harvard University Postdoctoral Fellow Arpita Biswas (opens in new tab), and Microsoft Research Senior Principal Researcher Akash Lal.
For more information about QL, read our paper “Learning-Based Controlled Concurrency Testing,” and to learn more about Coyote, watch the Tech Minutes: Project Coyote video (opens in new tab). You can also try out QL using this virtual machine with everything installed (opens in new tab). Happy bug finding!