

In February, we announced DeepSpeed, an open-source deep learning training optimization library, and ZeRO (Zero Redundancy Optimizer), a novel memory optimization technology in the library, which vastly advances large model training by improving scale, speed, cost, and usability. DeepSpeed has enabled researchers to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters. From there, we have been continuing to innovate at a fast rate, pushing the boundaries of speed and scale for deep learning training. Today, we are happy to share our new findings and results as we introduce the improved ZeRO-2 and further developments with DeepSpeed:
- An order-of-magnitude larger and faster training with ZeRO-2: ZeRO-2 expands the scope of memory optimizations in the original ZeRO by tackling the full spectrum of memory consumption during training. More specifically, ZeRO-2 introduces new technology to reduce the memory footprint of gradients, activation memory, and fragmented memory, in addition to optimizer state memory optimization in the original ZeRO. Altogether, the memory savings empower DeepSpeed to improve the scale and speed of deep learning training by an order of magnitude. More concretely, ZeRO-2 allows training models as large as 170 billion parameters up to 10x faster compared to state of the art.
- Fastest BERT training: While ZeRO-2 optimizes large models during distributed training, we also introduce new technology to accelerate single GPU performance via kernel optimizations. These optimizations not only create a strong foundation for scaling out large models, but also improve the single GPU performance of highly tuned and moderately sized models like BERT by more than 30%, reaching a staggering performance of 64 teraflops per V100 GPU, which is over 50% of the hardware peak. Using these optimizations as the building block, DeepSpeed achieves the fastest BERT training record: 44 minutes on 1,024 NVIDIA V100 GPUs, compared with the best published result of 67 minutes on the same number and generation of GPUs.
All of these exciting new optimizations are now available in our open-source library, DeepSpeed (opens in new tab). This work is an important part of Microsoft’s new AI at Scale (opens in new tab) initiative to enable next-generation AI capabilities at scale. This accompanying AI blog post (opens in new tab) sheds light on how DeepSpeed is changing the game in big ways for large-scale AI since its release just a few months ago.
ZeRO-2: Training models with 100 billion parameters up to 10x faster
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
The Zero Redundancy Optimizer (abbreviated ZeRO) is a novel memory optimization technology for large-scale distributed deep learning. Unlike existing technologies like data parallelism (that is efficient but can only support a limited model size) or model parallelism (that can support larger model sizes but requires significant code refactoring while adding communication overhead that limits efficiency), ZeRO allows fitting larger models in memory without requiring code refactoring while remaining very efficient. ZeRO does so by eliminating the memory redundancy that is inherent in data parallelism while limiting the communication overhead to a minimum.
ZeRO removes the memory redundancies across data-parallel processes by partitioning the three model states (optimizer states, gradients, and parameters) across data-parallel processes instead of replicating them. By doing this, it boosts memory efficiency compared to classic data-parallelism while retaining its computational granularity and communication efficiency.
In our February release of DeepSpeed, we included optimizations to reduce optimizer state memory (ZeRO-1). Today, we release ZeRO-2, which extends ZeRO-1 by including optimization to reduce gradient memory, while also adding optimizations that target activation memory and fragmented memory. Compared with ZeRO-1, ZeRO-2 doubles the model size that can be trained with DeepSpeed while significantly improving the training efficiency. With ZeRO-2, a 100-billion-parameter model can be trained 10x faster than with the state-of-art technology based on model parallelism alone.
ZeRO-2 deep dive: Reducing gradients, activation, and fragmented memory
ZeRO-2 optimizes the full spectrum of memory consumption during deep learning training, which includes model state (such as optimizer states and gradients), activation memory, and fragmented memory. Figure 1 shows the key techniques in ZeRO-2, and the details are below.
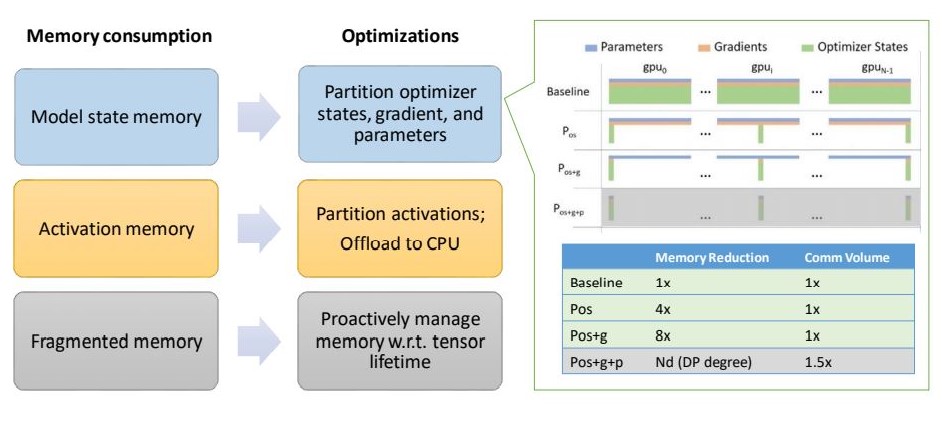
Figure 1: ZeRO-2 optimization overview. Going beyond ZeRO-1, which optimizes partitioning optimizer states (Pos), ZeRO-2 introduces new technology to reduce the memory footprint of partitioning gradients (Pos+g), activation memory, and fragmented memory, tackling the full spectrum of memory optimizations.
Model state memory: ZeRO has three accumulative stages to optimize model states. These states are partitioning optimizer states (Pos), gradients (Pos+g), and parameters (Pos+g+p) respectively. The ZeRO-1 implementation we shared in February supports the first stage, partitioning optimizer states (Pos), which saves up to 4x of memory when compared with using classic data parallelism that replicates everything. ZeRO-2 adds the support for the second stage, partitioning gradients (Pos+g), which reduces per-device memory consumption by another 2x, on top of the first stage’s 4x reduction. Compared with default data parallelism, ZeRO-2 obtains up to 8x memory saving on model states, with the same communication volume.
Activation memory: After optimizing model states, we notice that activations (stored from forward pass in order to perform backward pass) can be a secondary memory bottleneck. Activation checkpointing helps, but it is not sufficient for very large models. ZeRO-2 introduces new techniques to remove activation replication in existing model parallelism approaches through activation partitioning. It also offloads activation memory to the host CPUs when appropriate.
Fragmented memory: We observe fragmented memory during training due to variations in the lifetime of different tensors. Lack of contiguous memory due to fragmentation can cause memory allocation failure, even when enough free memory is available. ZeRO-2 proactively manages memory based on the different lifetime of tensors, preventing memory fragmentation.
ZeRO-2 evaluation: Advancing size, speed, scalability, and usability
ZeRO-2 excels in four aspects (as visualized in Figure 2), supporting an order-of-magnitude bigger models, up to 10x faster, with superlinear scalability, and improved usability to democratize large model training. These four aspects are detailed below.
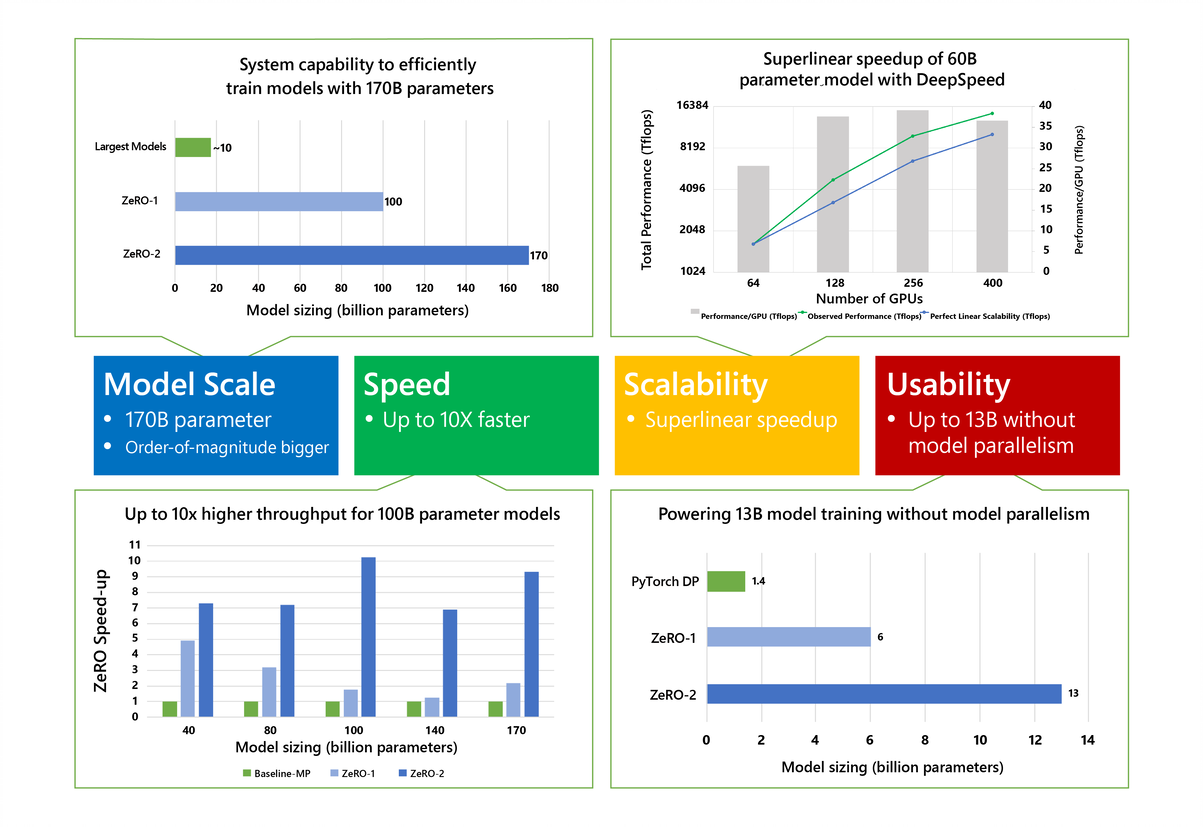
Figure 2: ZeRO-2 scales to 170 billion parameters, has up to 10x higher throughput, obtains superlinear speedup, and improves usability by avoiding the need for code refactoring for models up to 13 billion parameters.
Model scale: State-of-the-art large models (trained without using ZeRO) such as OpenAI GPT-2, NVIDIA Megatron-LM, and Google T5 have sizes of 1.5B, 8.3B, and 11B parameters respectively. ZeRO-2 provides system capability to efficiently run models of 170 billion parameters, an order-of-magnitude bigger than these largest models (Figure 2, top left). The tests were conducted using 400 NVIDIA V100 GPUs; with more devices (such as 1,000 GPUs), ZeRO-2 allows us to scale toward 200 billion parameters.
Speed: Improved memory efficiency powers higher throughput and faster training. Figure 2 (bottom left) shows system throughput of ZeRO-2, ZeRO-1, and baseline model parallelism. Here we use a state-of-the-art model parallelism approach, NVIDIA Megatron-LM (opens in new tab), as baseline-MP, while ZeRO-2 and ZeRO-1 both combine ZeRO-powered data parallelism with Megatron-LM model parallelism. ZeRO-2 runs 100-billion-parameter models with over 38 teraflops per GPU, 30% of hardware peak, and aggregated performance over 15 petaflops on the cluster with 400 NVIDIA V100 GPUs. For models of the same size, ZeRO-2 is up to 10x faster in training speed when compared to the baseline because model parallelism requires high communication bandwidth to be efficient, and models of these sizes require model parallelism across nodes where the communication bandwidth is limited. The memory savings of ZeRO-2 allows us to reduce model parallelism degree and fit the model without requiring inter-node model parallelism, drastically reducing communication cost. ZeRO-2 is also up to 5x faster than ZeRO-1 because its additional memory savings help reduce communication further and support even larger batch sizes.
Scalability: We observe superlinear speedup (Figure 2, top right), where the performance more than doubles when the number of NVIDIA GPUs are doubled. ZeRO-2 reduces the memory footprint of the model states as we increase the data parallelism degree, allowing us to fit larger batch sizes per GPU and resulting in better performance.
Democratizing large model training: ZeRO-2 empowers model scientists to train models up to 13 billion parameters efficiently without any model parallelism that typically requires model refactoring (Figure 2, bottom right). 13 billion parameters is larger than most of the largest state-of-the-art models (such as Google T5, with 11 billion parameters). With respect to throughput, we observe an average throughput of 37 teraflops (30% hardware peak) per V100 GPU for model sizes ranging from 2 billion to 13 billion parameters. Model scientists can therefore experiment freely with large models without worrying about model parallelism. In comparison, the implementations of classic data parallelism approaches (such as PyTorch Distributed Data Parallel) run out of memory with 1.4-billion-parameter models, while ZeRO-1 supports up to 6 billion parameters.
For more details about ZeRO-2, please see the DeepSpeed GitHub repository (opens in new tab) and the updated ZeRO paper.
Achieving the fastest and most efficient BERT training with DeepSpeed
While ZeRO primarily benefits large models during distributed training across a cluster of devices, we also introduce new technology, highly optimized transformer kernels and asynchronous I/O, that boosts compute and I/O speed of training on each individual GPU. This line of optimizations not only builds a solid basis when scaling out large models, but also squeezes out the last bit of already optimized performance while training moderately sized models like BERT.
We achieve the fastest BERT training record: 44 minutes on 1,024 NVIDIA V100 GPUs. Furthermore, the improved training time is not at the cost of excessive hardware resources but comes from software-boosted efficiency: We improve training throughput by over 30% when compared with the best results on the same number and generation of GPUs. We observe 64 teraflops of throughput on a single V100 GPU, achieving over 50% of hardware peak.
Let’s start by first looking at single GPU performance. Figure 3 shows the single V100 GPU throughput achieved with DeepSpeed for training BERT-Large, compared with two well-known implementations, NVIDIA BERT (opens in new tab) and HuggingFace BERT (opens in new tab). DeepSpeed reaches throughput as high as 64 and 53 teraflops (corresponding to 272 and 52 samples/second) for sequence lengths of 128 and 512, respectively, exhibiting up to 28% throughput improvements over NVIDIA BERT and up to 62% over HuggingFace BERT. We also support up to 1.8x larger batch size without running out of memory.
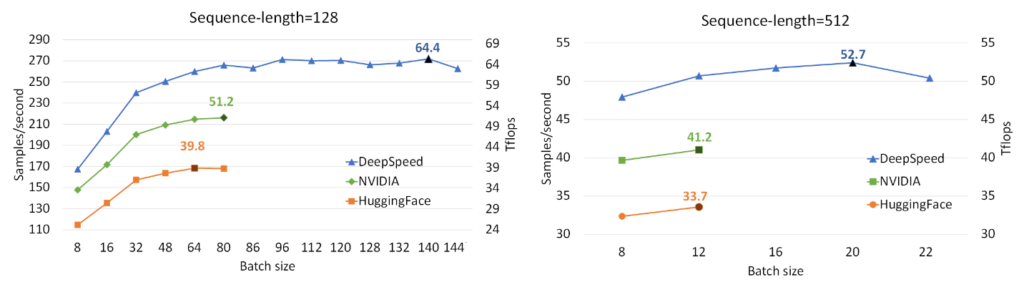
Figure 3: Performance evaluation of BERT-Large on a single V100 GPU, comparing DeepSpeed with NVIDIA and HuggingFace versions of BERT in mixed-sequence length training and with gradient accumulation step of 10. The labeled points show the highest throughput of each implementation in teraflops (Tflops). DeepSpeed boosts throughput and allows for higher batch sizes without running out of memory.
Looking at distributed training across GPUs, Table 1 shows our end-to-end BERT-Large pretraining time (F1 score of 90.5 for SQUAD) using 16 to 1,024 GPUs. We complete BERT pretraining in 44 minutes using 1,024 V100 GPUs (64 NVIDIA DGX-2 nodes). Compared to the best-known result (opens in new tab) from NVIDIA that takes 47 minutes using 1,472 V100 GPUs, DeepSpeed is faster while using 30% less resources. While using 1,024 GPUs, NVIDIA BERT takes 67 minutes, and DeepSpeed takes 44 minutes, reducing training time over 30%. Similarly, on 256 GPUs, NVIDIA BERT takes 236 minutes while DeepSpeed takes 144 minutes.
| Number of nodes | Number of V100 GPUs | Time |
| 1 DGX-2 | 16 | 33 hr 13 min |
| 4 DGX-2 | 64 | 8 hr 41 min |
| 16 DGX-2 | 256 | 144 min |
| 64 DGX-2 | 1,024 | 44 min |
Table 1: BERT-Large training time using 1 to 64 DGX-2s with DeepSpeed.
Even higher throughput could be obtained by combining our software optimizations with new hardware such as the NVIDIA A100 Tensor Core GPU, which has 2.5x hardware peak performance of the V100 GPU. Assuming the A100 GPU allows us to obtain the same percentage of hardware peak performance (50%) as we obtained on V100 GPUs, that could potentially reduce BERT training time further to less than 25 minutes on a cluster of 1,024 A100 GPUs.
The system performance improvements of DeepSpeed on BERT pretraining primarily come from our highly optimized transformer kernels, where we employ two lines of optimizations.
First, we observe that transformer-based networks trigger many invocations of NVIDIA CUDA kernels operating in a producer-consumer fashion, which creates excess read/write requests to memory. This pattern is a perfect match for kernel fusion, and we developed fused transformer-kernels to reduce data movement. Furthermore, in the fused kernel, we distribute data processing among NVIDIA GPU cores in a way to reduce the synchronization and data communication between them. DeepSpeed leverages these optimized fused transformer-kernels to maximize data reuse and improve computation efficiency on GPUs.
Second, we leverage invertible operators to save memory and support large batch size. Invertible operators are those whose backward pass is independent of the inputs and can be formulated based only on the outputs. We have seen that several operators of transformer have such behavior, including Softmax and Layer Norm. By leveraging their invertible property, we drop the inputs to these layers to reduce the footprint of activation memory. An example of the original and invertible Softmax computation is shown in Figure 4, where the invertible version reduces the activation memory of the operator by half. Reduced activation memory allows us to fit larger batch sizes, which often leads to higher efficiency.
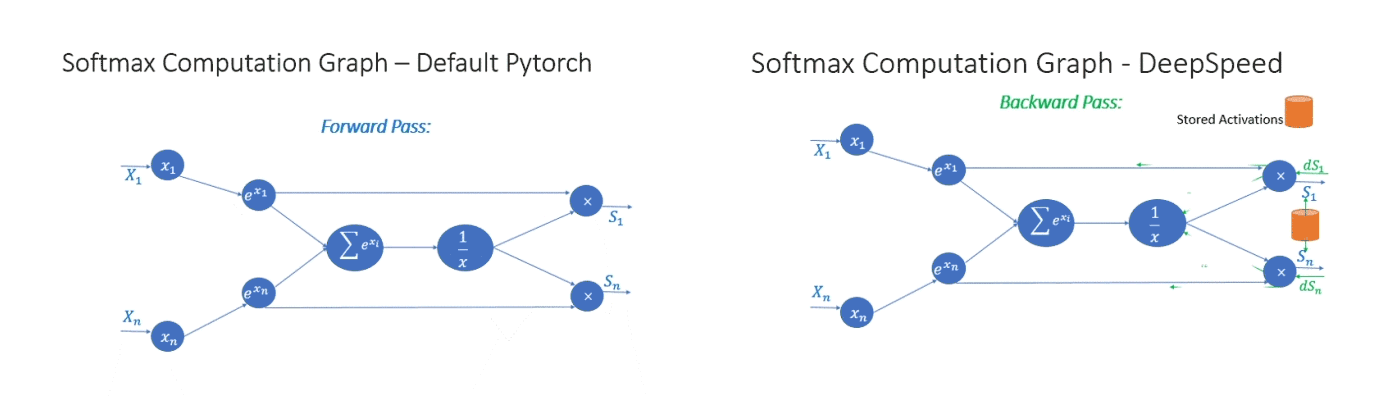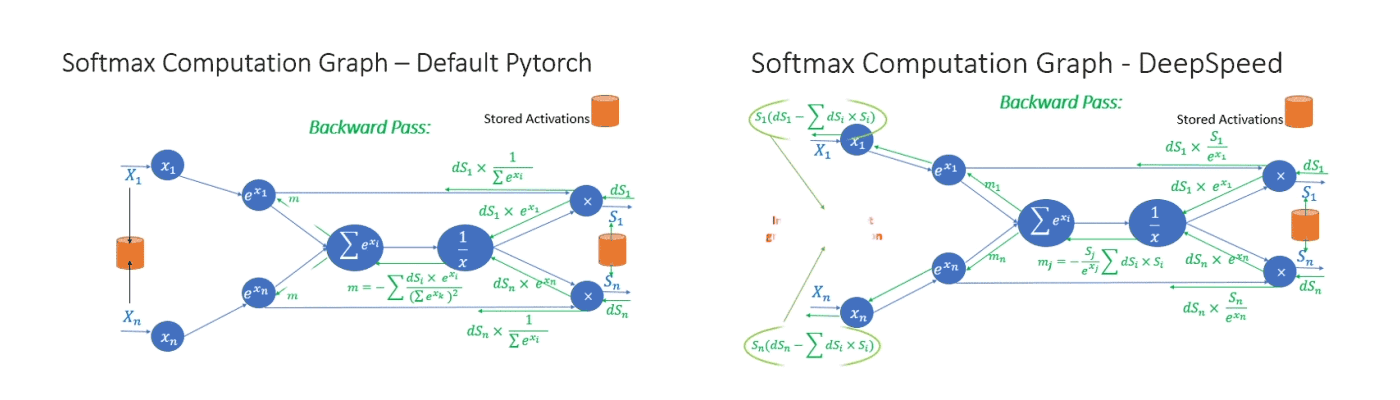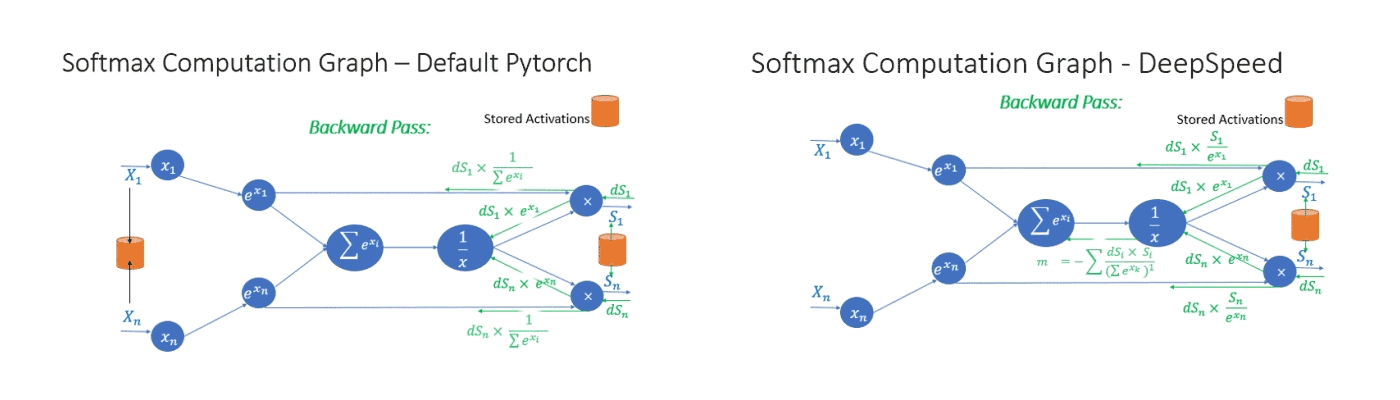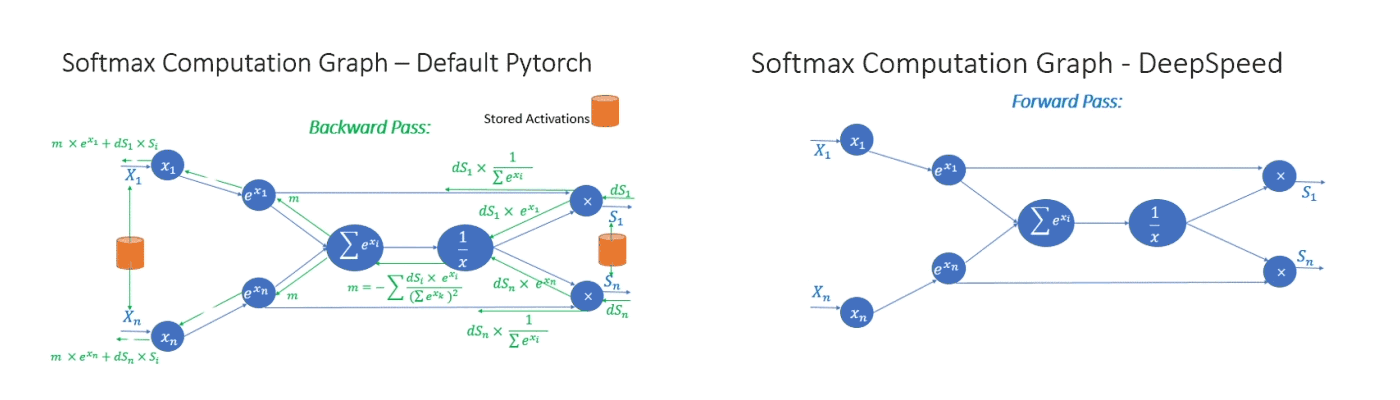
Figure 4: Default PyTorch Softmax operation versus DeepSpeed invertible Softmax operation.
In addition to optimized kernels, we employ asynchronous I/O to overlap computation with communication, leverage pre-layer norm that allows higher learning rate and faster convergence, and reduce redundant calculation at the output layer.
Altogether, these techniques optimize BERT training time and efficiency. Furthermore, most of these optimizations are not BERT specific. Instead they are generic optimization strategies applicable across a wide range of workloads. For example, we package the highly optimized kernels as custom transformer operators, which are easily reusable in other transformer-based models.
More updates of DeepSpeed, codes, tutorials and technical deep dive blogs are available in DeepSpeed.ai (opens in new tab).
About the DeepSpeed Team: We are a group of system researchers and engineers—Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Reza Yazdani Aminabadi, Elton Zheng, Arash Ashari, Jing Zhao, Minjia Zhang, Niranjan Uma Naresh, Shaden Smith, Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop!




