
 The latest trend in AI is that larger natural language models provide better accuracy; however, larger models are difficult to train because of cost, time, and ease of code integration. Microsoft is releasing an open-source library called DeepSpeed (opens in new tab), which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models. DeepSpeed is compatible with PyTorch (opens in new tab). One piece of that library, called ZeRO, is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained. Researchers have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post.
The latest trend in AI is that larger natural language models provide better accuracy; however, larger models are difficult to train because of cost, time, and ease of code integration. Microsoft is releasing an open-source library called DeepSpeed (opens in new tab), which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models. DeepSpeed is compatible with PyTorch (opens in new tab). One piece of that library, called ZeRO, is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained. Researchers have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post.
The Zero Redundancy Optimizer (abbreviated ZeRO) is a novel memory optimization technology for large-scale distributed deep learning. ZeRO can train deep learning models with 100 billion parameters on the current generation of GPU clusters at three to five times the throughput of the current best system. It also presents a clear path to training models with trillions of parameters, demonstrating an unprecedented leap in deep learning system technology. We are releasing ZeRO as part of DeepSpeed, our high-performance library for accelerating distributed deep learning training.
Challenges of training large deep learning models
Large models offer significant accuracy gains, but training billions to trillions of parameters frequently runs up against fundamental hardware limitations. To fit these models into memory, existing solutions make trade-offs between computation, communication, and development efficiency:
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
• Data parallelism does not help reduce memory footprint per device: a model with more than 1 billion parameters runs out of memory even on GPUs with 32GB of memory.
• Model parallelism does not scale efficiently beyond a single node due to fine-grained computation and expensive communication. Model parallelism frameworks frequently require extensive code integration that may be model architecture specific. For example, the NVIDIA Megatron-LM (opens in new tab) set a new model size record of 8.3 billion parameters. It scales very well for such a model that fits in multiple GPUs of a single node, but when scaling across nodes, its performance degrades. For example, we observe about five teraflops/GPU when running 40 billion parameters across NVIDIA DGX-2 nodes.
Overcoming limitations of data parallelism and model parallelism with ZeRO
We developed ZeRO to conquer the limitations of data parallelism and model parallelism while achieving the merits of both. ZeRO removes the memory redundancies across data-parallel processes by partitioning the model states—parameters, gradients, and optimizer state—across data parallel processes instead of replicating them. It uses a dynamic communication schedule during training to share the necessary state across distributed devices to retain the computational granularity and communication volume of data parallelism.
We call this ZeRO-powered data parallelism, which allows per-device memory usage to scale linearly with the degree of data parallelism and incurs similar communication volume as data parallelism. ZeRO-powered data parallelism can fit models of arbitrary size—as long as the aggregated device memory is large enough to share the model states.
The three stages of ZeRO and its benefits
ZeRO has three main optimization stages (as depicted in Figure 1), which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
1. Optimizer State Partitioning (Pos) – 4x memory reduction, same communication volume as data parallelism
2. Add Gradient Partitioning (Pos+g) – 8x memory reduction, same communication volume as data parallelism
3. Add Parameter Partitioning (Pos+g+p) – Memory reduction is linear with data parallelism degree Nd. For example, splitting across 64 GPUs (Nd = 64) will yield a 64x memory reduction. There is a modest 50% increase in communication volume.
ZeRO eliminates memory redundancies and makes the full aggregate memory capacity of a cluster available. With all three stages enabled, ZeRO can train a trillion-parameter model on just 1024 NVIDIA GPUs. A trillion-parameter model with an optimizer like Adam (opens in new tab) in 16-bit precision requires approximately 16 terabytes (TB) of memory to hold the optimizer states, gradients, and parameters. 16TB divided by 1024 is 16GB, which is well within a reasonable bound for a GPU.
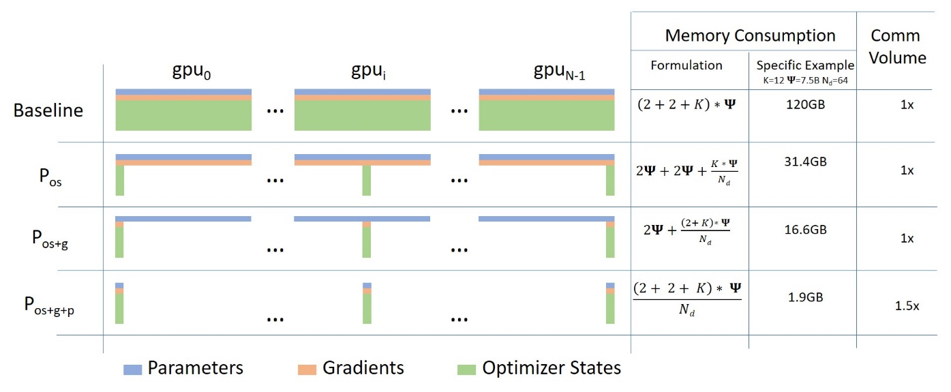
Figure 1: Memory savings and communication volume for the three stages of ZeRO compared with standard data parallel baseline. In the memory consumption formula, Ψ refers to the number of parameters in a model and K is the optimizer specific constant term. As a specific example, we show the memory consumption for a 7.5B parameter model using Adam (opens in new tab) optimizer where K=12 on 64 GPUs. We also show the communication volume of ZeRO relative to the baseline.
The video below shows how ZeRO (with all three stages) performs a training step including forward pass, backward pass, and parameter update.
DeepSpeed: PyTorch compatibility and system performance
We implemented ZeRO stage one — optimizer states partitioning (ZeRO-OS in short) — which has a demonstrated capability to support 100-billion-parameter models. The code is being released together with our training optimization library, DeepSpeed. DeepSpeed brings state-of-the-art training techniques, such as ZeRO, distributed training, mixed precision, and checkpointing, through lightweight APIs compatible with PyTorch (opens in new tab). With just a few lines of code changes to your PyTorch model, you can leverage DeepSpeed to address the underlying performance challenges and boost the speed and scale of your training.
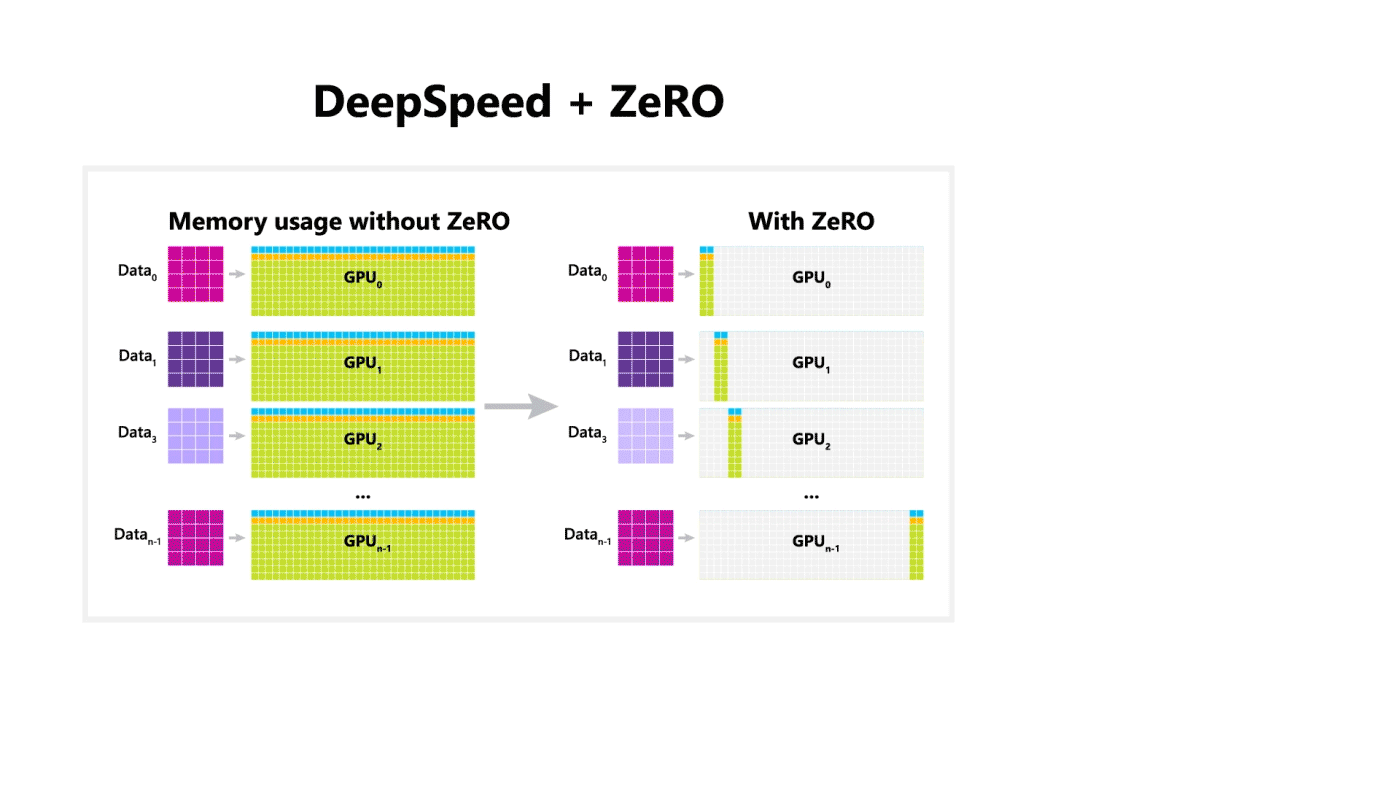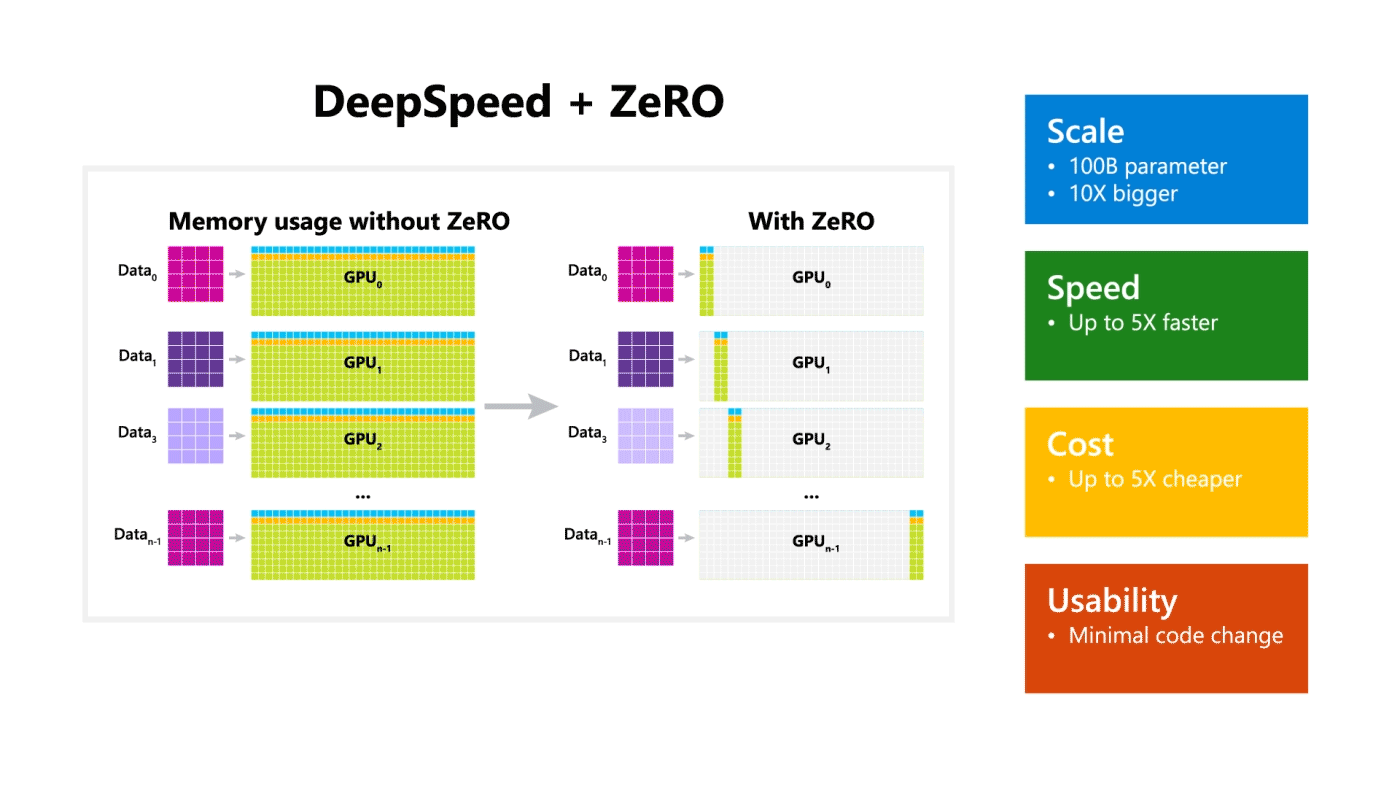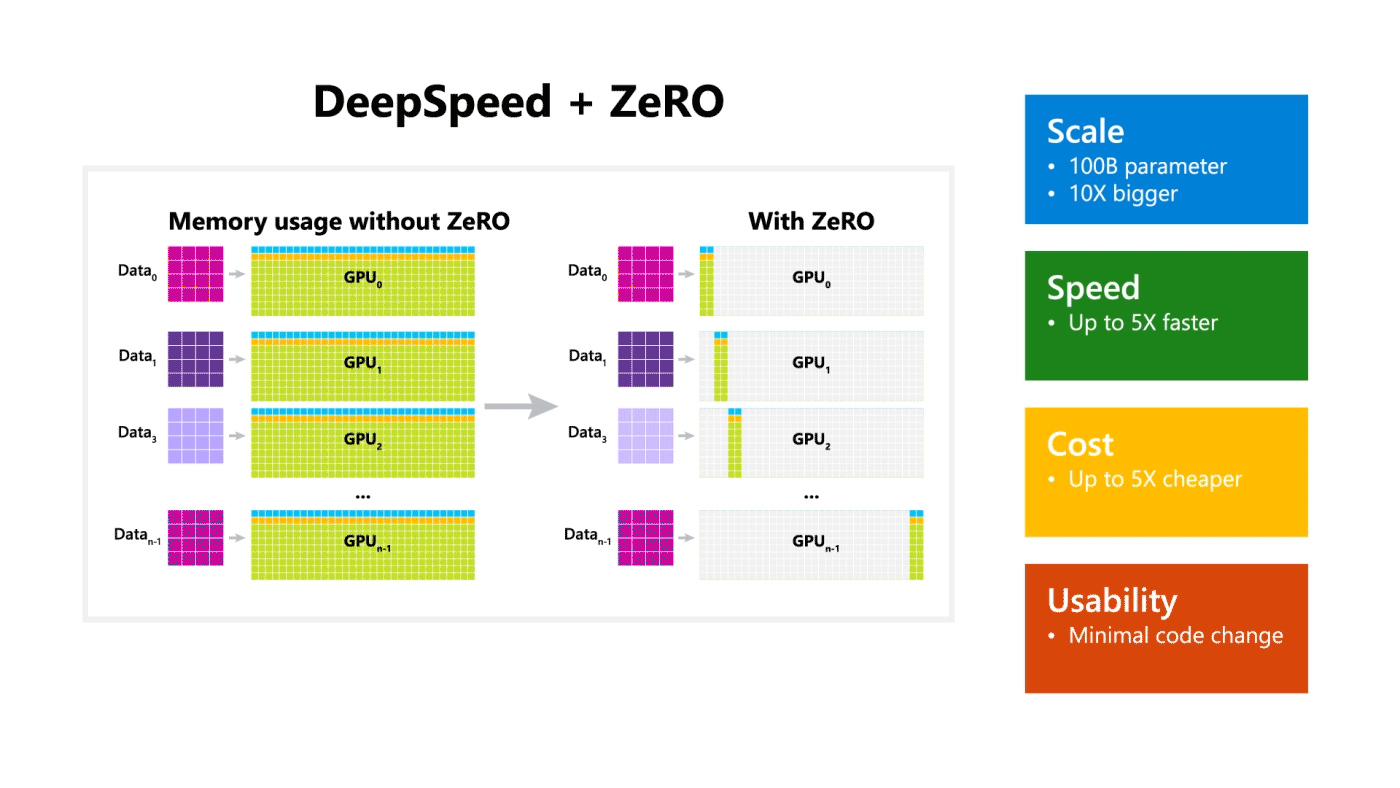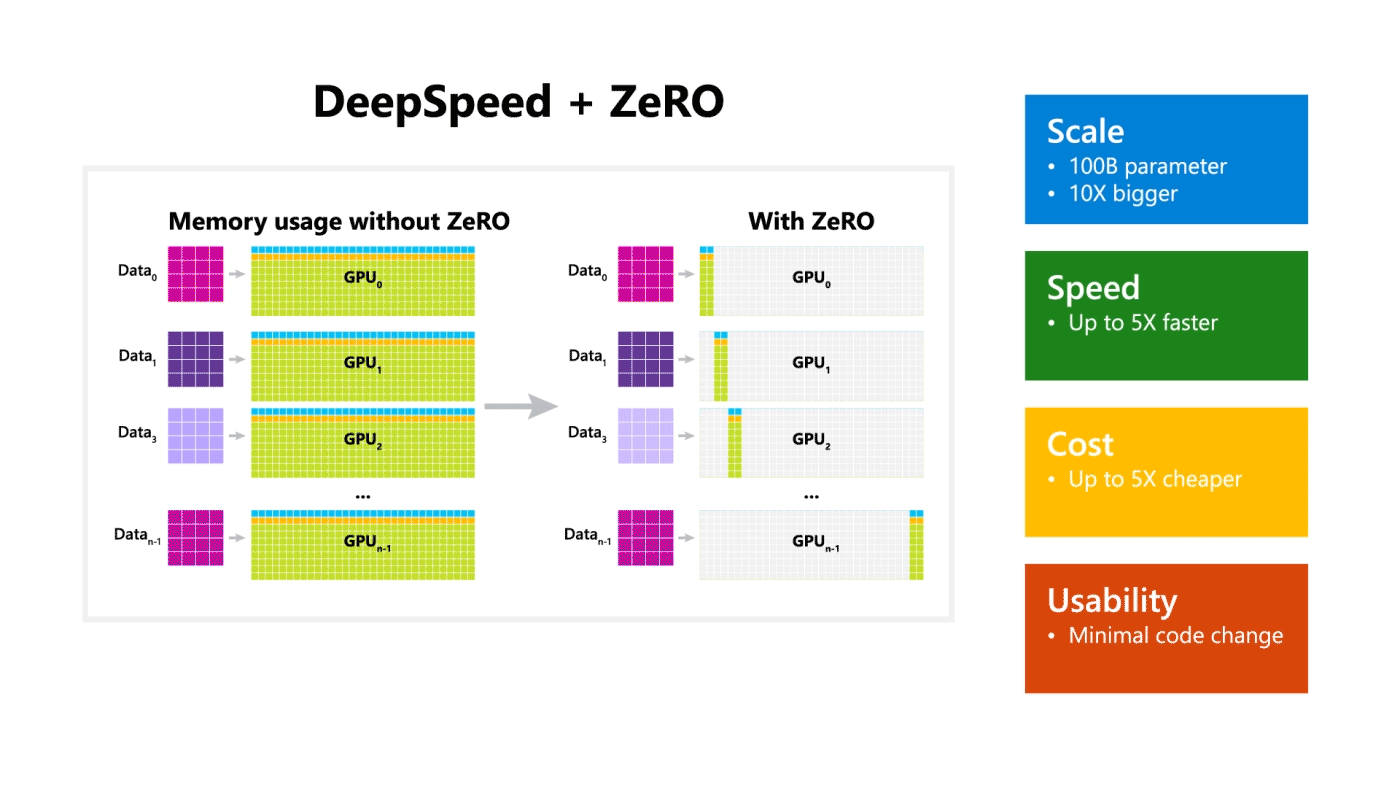
DeepSpeed excels in four aspects (as visualized in Figure 2):
• Scale: State-of-the-art large models such as OpenAI GPT-2, NVIDIA Megatron-LM, and Google T5 have sizes of 1.5 billion, 8.3 billion, and 11 billion parameters respectively. ZeRO stage one in DeepSpeed provides system support to run models up to 100 billion parameters, 10 times bigger. In the future, we plan to add support for ZeRO stages two and three, unlocking the ability to train models with 200 billion parameters to trillions of parameters.
• Speed: We observe up to five times higher throughput over state of the art across various hardware. For example, to train large models on GPT family of workloads, DeepSpeed combines ZeRO-powered data parallelism with NVIDIA Megatron-LM model parallelism. On NVIDIA GPU clusters with low-bandwidth interconnect (without NVIDIA NVLink or Infiniband), we achieve a 3.75x throughput improvement over using Megatron-LM alone for a standard GPT-2 model with 1.5 billion parameters. On NVIDIA DGX-2 clusters with high-bandwidth interconnect, for models of 20 to 80 billion parameters, we are three to five times faster. These throughput improvements come from DeepSpeed’s higher memory efficiency and ability to fit these models using a lower degree of model parallelism and larger batch sizes.
• Cost: Improved throughput can be translated to significantly reduced training cost. For example, to train a model with 20 billion parameters, DeepSpeed requires three times fewer resources.
• Usability: Only a few lines of code changes are needed to enable a PyTorch model to use DeepSpeed and ZeRO. Compared to current model parallelism libraries, DeepSpeed does not require a code redesign or model refactoring. It also does not put limitations on model dimensions (such as number of attention heads, hidden sizes, and others), batch size, or any other training parameters. For models of up to six billion parameters, you can use data parallelism (powered by ZeRO) conveniently without requiring model parallelism, while in contrast, standard data parallelism will run out of memory for models with more than 1.3 billion parameters. ZeRO stages two and three will further increase the model size trainable with data parallelism alone. In addition, DeepSpeed supports flexible combination of ZeRO-powered data parallelism with model parallelism.
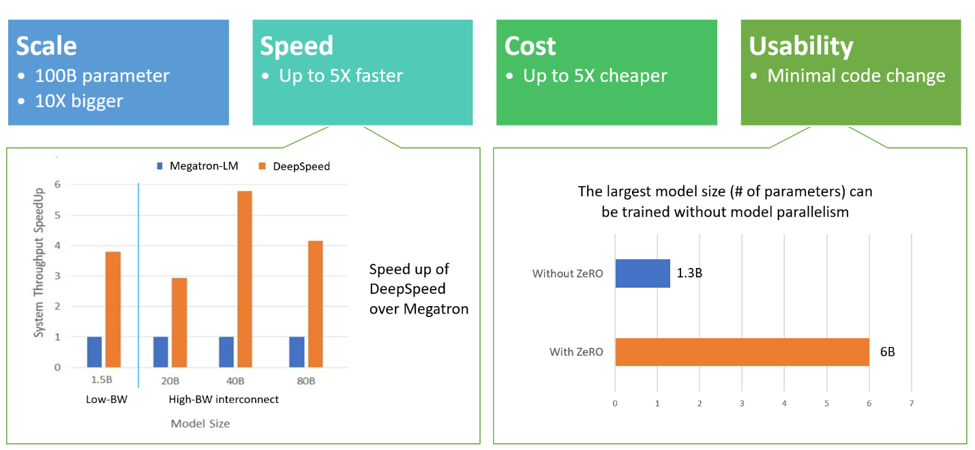
Figure 2: DeepSpeed excels in scale, speed, cost and usability. The bottom left figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of Megatron-LM) over using Megatron-LM alone. The bottom right figure compares trainable model size using data parallelism alone with and without ZeRO.
Turing-NLG and DeepSpeed-powered large model training
We leveraged ZeRO-OS in DeepSpeed to train a 17-billion-parameter Turing-NLG model with higher accuracy and higher training efficiency than current state-of-the-art approaches. Please refer to this blog, which shows the new accuracy records the model establishes and its wide applications on free-form text generation, summarization, and answer synthesis.
ZeRO-OS is complementary and compatible with different types of model parallelism, and for large models that do not fit into a single node (around 20 billion parameters or more), it offers significant performance gains, resource savings, and flexibility in model design compared to using model parallelism alone.
We use ZeRO-OS in combination with Megatron-LM from NVIDIA in DeepSpeed to train the Turing-NLG model. The memory savings from ZeRO-OS allows the Turning-NLG model to be run with 4x smaller model parallelism degree and 4x larger batch size compared to using NVIDIA Megatron-LM alone. As a result we achieve 3x throughput gain. Additionally, we can train at batch size of 512 with only 256 GPUs compared to 1024 GPUs needed with Megatron-LM alone. Finally, Megatron-LM cannot run this exact model—the model structure is not supported because its attention head (=28) is not divisible by the model parallelism degree (=16). DeepSpeed takes the model from infeasible to run to feasible and efficient to train!
For more details, please see the DeepSpeed GitHub (opens in new tab) repository and the ZeRO paper. We are also working with the ONNX and ONNX Runtime communities for further integration of these techniques.
About the DeepSpeed Team: We are a group of system researchers and engineers—Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Arash Ashari, Elton Zheng, Jing Zhao, Minjia Zhang, Niranjan Uma Naresh, Reza Yazdani Aminabadi, Shaden Smith, Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing its speed to train, speed to convergence, and speed to develop!
If this type of work interests you, the DeepSpeed team is hiring! Please visit our careers page (opens in new tab).




