

LaTTe paper (opens in new tab) and video (opens in new tab) | Trajectory Transformer paper (opens in new tab) and video (opens in new tab) | Github code (opens in new tab)
Language is the most intuitive way for us to express how we feel and what we want. However, despite recent advancements in artificial intelligence, it is still very hard to control a robot using natural language instructions. Free-form commands such as “Robot, please go a little slower when you pass close to my TV” or “Stay far away from the swimming pool!” are hard to parse into actionable robot behaviors, and most human-robot interfaces today still rely on complex strategies such directly programming cost functions which define the desired behavior.
With our latest work, we attempt to change this reality through the introduction of “LaTTe: Language Trajectory Transformer” (opens in new tab). LaTTe is a deep machine learning model that lets us send language commands to robots in an intuitive way with ease. When given an input sentence by the user, the model fuses it with camera images of objects that the robot observes in its surroundings, and outputs the desired robot behavior.
As an example, think of a user trying to control a robot barista that’s moving a wine bottle. Our method allows a non-technical user to control the robot’s behavior only using words, in a natural and simple interface. We will explain how we can achieve this in detail through this post.


Continue reading to learn more about this technology, or check out these additional resources:
- Read the technical details of the model architecture in our two papers: LaTTe (opens in new tab) [in submission] and Trajectory Language Transformer (opens in new tab) [IROS 2022]
- Check out the project’s webpage (opens in new tab)
- View our machine learning models on our Github repository (opens in new tab)
We also invite the reader to watch the videos describing the papers:
Unlocking the potential of language for robotics
The field of robotics traditionally uses task-specific programming modules, which need to be re-designed by an expert even if there are minor changes in robot hardware, environment, or operational objectives. This inflexible approach is ripe for innovation with the latest advances in machine learning, which emphasizes reusable modules that generalize well over large domains.
Given the intuitive and effective nature of language for general communication, it would be simpler if one could just tell the robot how they want it to behave as opposed to having to reprogram the entire stack every time a change is needed. While large language models such as BERT (opens in new tab), GPT-3 (opens in new tab) and Megatron-Turing have radically improved the quality of machine-generated text and our ability to solve to natural language processing tasks, and models like CLIP extend our reach capabilities towards multi-modal domains with vision and language, we still see few examples of language being applied in robotics.
The goal of our work is to leverage information contained in existing vision-language pre-trained models to fill the gap in existing tools for human-robot interaction. Even though natural language is the richest form of communication between humans, modeling human-robot interactions using language is challenging because we often require vast amounts of data to train models, or classically, force the user to operate within a rigid set of instructions. To tackle these challenges, our framework makes use of two key ideas: first, we employ large pre-trained language models to provide rich user intent representations, and second, we align geometrical trajectory data with natural language jointly with the use of a multi-modal attention mechanism.
We test our model on multiple robotic platforms, from manipulators to drones, and show that its functionality is agnostic of the robot form factor, dynamics, and motion controller. Our goal is to enable a factory worker to quickly reconfigure a robot arm trajectory further away from fragile objects; or allow a drone pilot to command the drone to slow down when close to buildings – all without requiring immense technical expertise.
Combining language and geometry into a single robotics model
Our overall goal is to provide a flexible interface for human-robot interaction within the context of trajectory reshaping that is agnostic to robotic platforms. We assume that the robot’s behavior is expressed through a 3D trajectory over time, and that the user provides a natural language command to reshape its behavior which relates to particular things in the scene, such as the objects in the robot workspace. Our trajectory generation system outputs a sequence of waypoints in XYZ and velocities, which are calculated fusing scene geometry, scene images, and the user’s language input. The diagram below shows an overview of the system:

LaTTe is composed of several building blocks, which can be categorized into the feature extractors, geometric encoder, and a final trajectory decoder. We use a pre-trained language model encoder, BERT, to produce semantic features from the user’s input. The use of a large language model creates more flexibility in the natural language input, allowing the use of synonyms and less training data, given that the encoder has already been trained with a massive text corpus. In addition, we use the pre-trained text encoder from the vision-language model CLIP to extract latent embeddings from both the user’s text and the pictures of each object in the scene. We then compute a similarity vector between the embeddings, and use this information to identify target objects the user is referring to through their language command.

As for the geometric information, we employ a Transformer encoder network to extract features related to the original robot’s trajectory as well as the 3D position of each one of the objects in the scene. In a practical scenario we can use off-the-shelf object detectors to obtain the position and pictures of each significant object.
Finally, all the geometrical, language and visual information is fused together into a Transformer decoder block. Similarly to what happens in a machine translation problem (for example, translating a sentence from English to German), the information from the transformer encoder network is used by the transformer decoder to generate one waypoint of the output trajectory at a time in a loop. The training process uses a range of procedurally generated synthetic data with multiple trajectory shapes and random object categories. We use multiple images for each object, which we obtain by web crawling through Bing Images (opens in new tab).
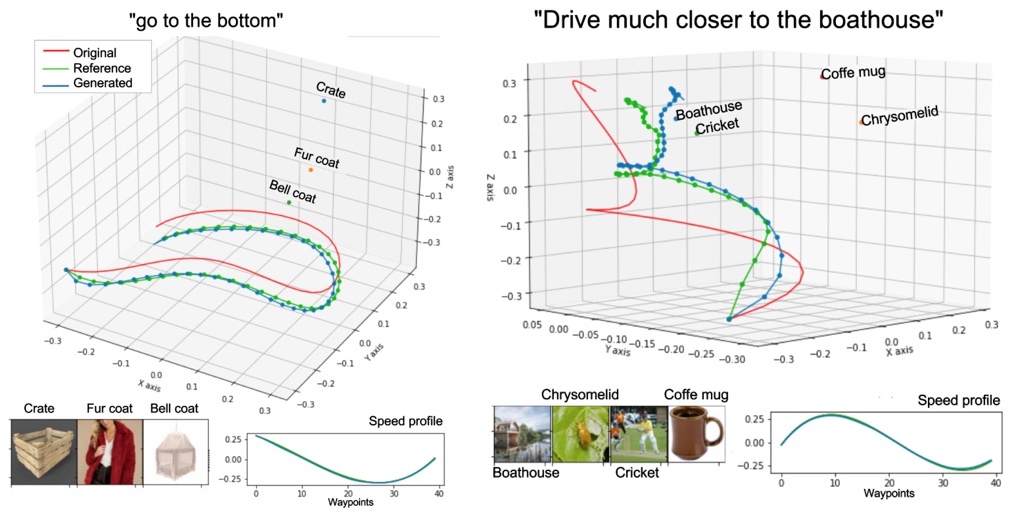
What can we do with this model?
We conducted several experiments in simulated and real-life environments to test the effectiveness of LaTTe. We also tested different form factors (manipulators, drones, and a hexapod robot) in a multitude of scenarios to show the capability of LaTTe to adapt to various robot platforms.
Examples with manipulators:


Examples with aerial vehicles:


Examples with a hexapod robot:
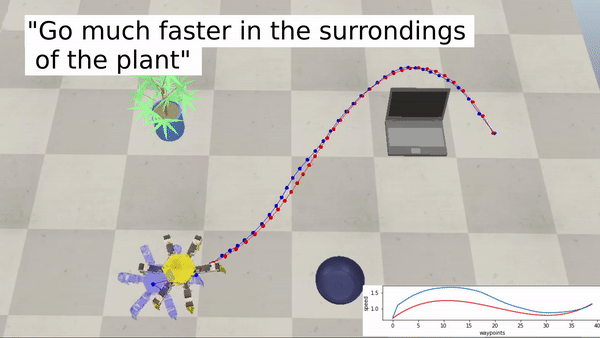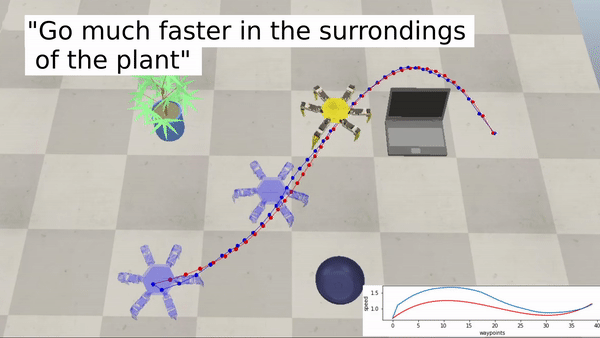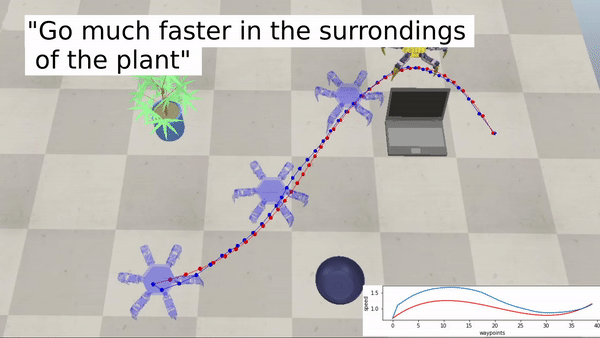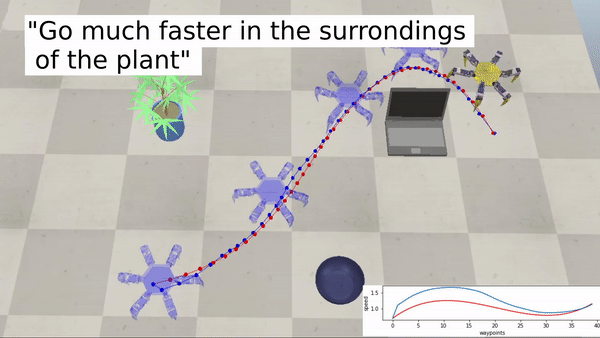
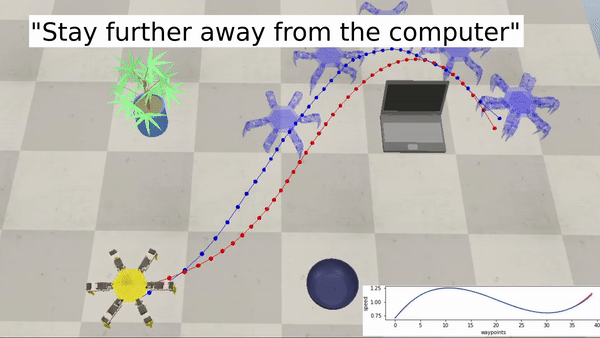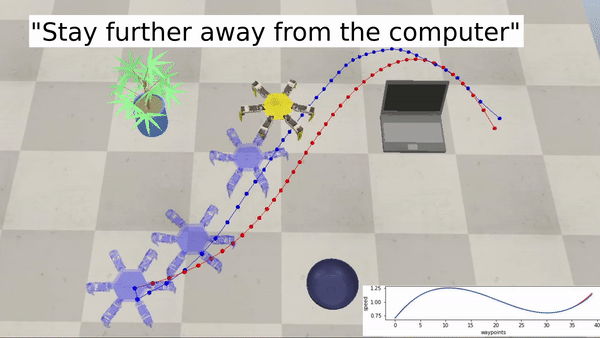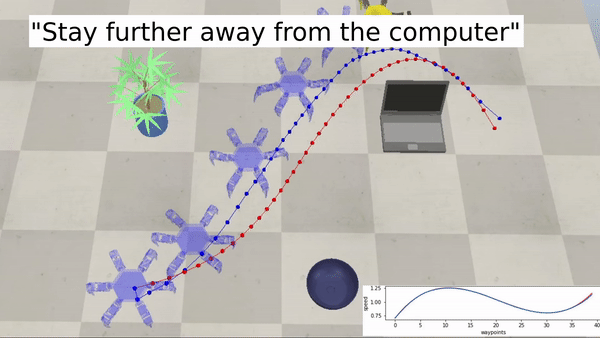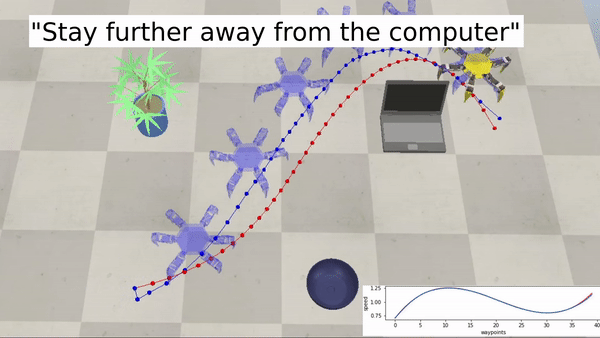
Bringing robotics to a wider audience
We are excited to release these technologies with the aim of bringing robotics to the reach of a wider audience. Given the burgeoning applications of robots in several domains, it is imperative to design human-robot interfaces that are intuitive and easy to use. Our goal when designing such interfaces is to afford flexibility and precision of action, while ensuring that little to no technical training is required for novel users. Our Language Trajectory Transformer (LaTTe) framework takes a big step forward towards this direction.
This work is being undertaken by a multidisciplinary team at Microsoft Autonomous Systems Research together with the Munich Institute of Robotics and Machine Intelligence (MIRMI (opens in new tab)) at TU Munich. The researchers included in this project are: Arthur Bucker (opens in new tab), Luis Figueredo (opens in new tab), Sami Haddadin (opens in new tab), Ashish Kapoor, Shuang Ma, Sai Vemprala and Rogerio Bonatti (opens in new tab).