

Over the past year, excitement around Large Language Models (LLMs) skyrocketed. With ChatGPT and BingChat, we saw LLMs approach human-level performance in everything from performance on standardized exams to generative art. However, many of these LLM-based features are new and have a lot of unknowns, hence require careful release to preserve privacy and social responsibility. While offline evaluation is suitable for early development of features, it cannot assess how model changes benefit or degrade the user experience in production. In fact, multiple explorations of GPT-4 capabilities suggest that “the machine learning community needs to move beyond classical benchmarking via structured datasets and tasks, and that the evaluation of the capabilities and cognitive abilities of those new models have become much closer in essence to the task of evaluating those of a human rather than those of a narrow AI model” [1]. Measuring LLM performance on user traffic in real product scenarios is essential to evaluate these human-like abilities and guarantee a safe and valuable experience to the end user. This is not only applicable for deploying a feature; In fact, continuous evaluation of features as they are being developed provides early insight into any regressions or negative user experience while also informing design decisions.
At Microsoft, the Experimentation Platform has worked closely with multiple teams to launch and evaluate LLM products over the past several months. We learned and developed best practices on how to design AB tests and metrics to evaluate such features accurately and holistically. In this article, we are sharing the standard set of metrics that are leveraged by the teams, focusing on estimating costs, assessing customer risk and quantifying the added user value. These metrics can be directly computed for any feature that uses OpenAI model (opens in new tab)s and logs their API response (opens in new tab).
GPU Utilization
To estimate the usage cost of an LLM, we measure the GPU Utilization of the LLM. The main unit we use for measurement is token. (opens in new tab) Tokens are pieces of words used for natural language processing. For Open AI models, 1 token is approximately 4 characters or 0.75 words in English text (opens in new tab). Prompts passed to LLM are tokenized (prompt tokens (opens in new tab)) and the LLM generates words that also get tokenized (completion tokens (opens in new tab)). LLMs output one token per iteration or forward pass, so the number of forward passes of an LLM required for a response is equal to the number of completion tokens.
We use the following primary utilization metrics – please check the appendix for a full list of metrics.
- Number of 429 responses (opens in new tab) received. A 429 error response is sent when the model and/or service is currently overloaded (opens in new tab). We recommend measuring the 95th or 90th percentile of the number of 429 responses to measure the peak performance.
- Total number of tokens, computed as the sum of prompt tokens and completion tokens. This is the main utilization metric we recommend for tracking for GPU Utilization. OpenAI charges based on the total number of tokens used by the prompt and response. (opens in new tab)
Responsible AI
As LLMs get used at large scale, it is critical to measure and detect any Responsible AI (opens in new tab) issues that arise. Azure OpenAI (opens in new tab) (AOAI) provides solutions to evaluate your LLM-based features and apps on multiple dimensions of quality, safety, and performance. Teams leverage those evaluation methods before, during and after deployment to minimize negative user experience and manage customer risk.
Moreover, the Azure Open AI Content filtering system (opens in new tab) captures and blocks some prompts and responses that have RAI issues. It also produces annotations (opens in new tab) and properties in the Azure Open AI API (opens in new tab) that we use to compute the following metrics.
- % Prompts with HTTP 400 error. This is the percentage of prompts that are classified at a filtered category and severity level.
- % Responses with “finish_reason”: “content_filter”. This is the percentage of responses that didn’t return content due to content filtering.
The annotations could be further used to provide stats for each filtering category (e.g. to what extent certain filtrations have happened).
Performance Metrics
As with any feature, measuring performance and latency is essential to ensure that the user is getting the intended value in a timely and frictionless manner. LLM interactions (opens in new tab)have multiple layers hence tracking and measuring latency at each layer is critical. If there are any orchestrator or added components between the LLM and the final rendering of the content, we also measure the latency for each of the components in the full workflow as well.
We use the following metrics to measure performance:
- Time to first token render from submission of the user prompt, measured at multiple percentiles.
- Requests Per Second (RPS) for the LLM.
- Tokens rendered per second when streaming (opens in new tab) the LLM response.
Utility Metrics
LLM features have the potential to significantly improve the user experience, however, they are expensive and can impact the performance of the product. Hence, it is critical to measure the user value they add to justify any added costs. While a product-level utility metric [2] functions as an Overall Evaluation Criteria (OEC) to evaluate any feature (LLM-based or otherwise), we also measure usage and engagement with the LLM features directly to isolate its impact on user utility.
Below we share the categories of metrics we measure. For a full list of the metrics, check the appendix.
User Engagement and Satisfaction
In this category, we measure how often the user engages with the LLM features, the quality of those interactions and how likely they are to use it in the future.
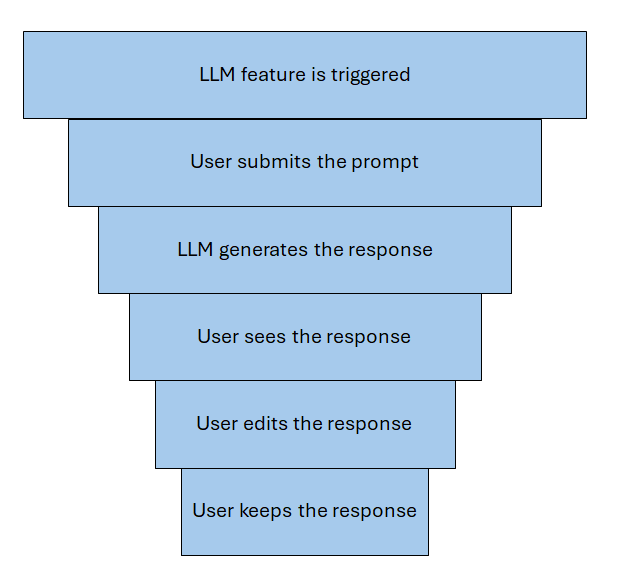
Some stages (e.g., editing the response) are not applicable to all scenarios (e.g., chat).
- Prompt and Response Funnel: As the user interacts with the LLM, prompts are sent in, and responses are sent back. We measure the usefulness of these responses and whether the user is in fact using them in their current task. The funnel tracks the interaction from the time the LLM is triggered until the user accepts or rejects the response.
- Prompt and Response Quality: Not all engagement with features provide value. To assess whether the user had a successful interaction with the LLM with minimal effort, we measure additional aspects that reflect quality of engagement: length of the prompt and response indicate whether they were meaningful, average edit distance (opens in new tab) between prompts indicate the user reformulating the same intent and Number of responses with Thumbs Up/Thumbs Down provide explicit feedback from the user on the quality of the response. Check out the appendix for detailed description of these metrics.
- Retention: These metrics measure how sticky the feature is and whether the user gets retained into the LLM feature. It is an important measure to detect any novelty effect where the usage drops after the initial engagement. Any retention metric that works for your product can be modified to focus on the LLM feature. Check the appendix for the ones we use.
Increase in productivity for collaboration scenarios
For scenarios where content can be created with AI and then consumed by users, we also recommend measuring any increase or improvement in productivity, both on the creation and consumption side. Such metrics measure the value-add beyond an individual user when the AI-generated content is used in a collaboration setting.
Data Requirements
To compute the metrics, the product needs to collect the properties needed from the OpenAI API (opens in new tab) response. Moreover, we recommend collecting the end user Id (opens in new tab) from the product’s telemetry to pass to the API.
For an LLM feature that can modify a user’s text directly, we add telemetry to differentiate user edits from machine or LLM edits. Otherwise, it will be hard to measure reduction in user-added characters or text when the LLM auto-completes the content.
Running A/B tests
A/B testing is the golden standard to causally measure the impact of any change to the product. As mentioned in the intro, this is even more critical for LLM features, both at launch time as well as subsequent improvements. The metrics we share above are then used to evaluate the changes and tradeoff costs and user value.
As you embark on the journey of launching an LLM-powered feature and innovating further, we recommend running the following types of experiments at launch and post launch of the feature.
Launch an LLM Feature
Ensure that the feature at launch is performant, reliable and increasing productivity and making the right cost v. benefit tradeoffs.
- Dark mode experiment: When launching an LLM Feature, we want to ensure that the feature at launch is performant and reliable. Before exposing the feature to end customers, we recommend running a dark mode experiment where the components for the feature are loaded without showing anything to the end customer.
- 0-1 Experiment: 0-1 experiments are special as the treatment has the LLM-powered feature and the control variant does not. We recommend rolling out the feature in a controlled rollout to ensure that you have enough GPU capacity and the product OEC and guardrail metrics are not affected, while you see an increase in productivity metrics.
Post Launch
Continue to innovate and optimize the feature to quickly address new customer needs through prompt optimization, using newer models, and UX improvements.
- Shadow Experiment: Before exposing a change in the LLM feature that changes the response shown to the user, we run shadow experiments to measure the impact in a low-risk and safe manner. Shadow experiments allow you to compute the treatment and control response for the same user, but only show them the control response. For example, when a user issues a query or prompt, the user’s input is fed into both the control workflow and the treatment workflow at the same time. All users get the response from the control workflow but now that we have both treatment and control responses on live traffic for the same user, hence metrics can be evaluated for both variants. Metrics are more sensitive than regular A/B tests as the treatment and control samples have exactly the same set of users leading to variance reduction. We can also get further sensitivity gains for by using paired samples t-tests (opens in new tab) in the statistical analysis. Metrics that could be measured in shadow experiments include GPU utilization, performance and latency, RAI metrics and prompt metrics that do not rely on user engagement. However, metrics that need user response cannot be evaluated in shadow experiments as no user experiences the treatment response.
- 1-N Experiment: These are the regular A/B tests we run to evaluate any change introduced to the product, including LLM features. Refer to our earlier blog posts on pre-experiment, during-experiment, and post-experiment patterns of trustworthy experimentation for best practices in this space.
Summary
LLMs can be a great tool to build features that add user value and increase their satisfaction with the product. However, properly testing and evaluating them is critical to safe release and added value. In this blog post, we shared a complete metrics framework to evaluate all aspects of LLM-based features, from costs, to performance, to RAI aspects as well as user utility. These metrics are applicable to any LLM but also can be built directly from telemetry collected from AOAI models. We also described the various experimentation designs used at Microsoft to evaluate the features at release time and continuously through any change.
Acknowledgements
Many thanks to our colleagues in Azure Open AI, particularly Sanjay Ramanujan, for all their input on the API responses as well as for ExP’s experimenting partners for testing and using the metrics.
Widad Machmouchi, Somit Gupta – Experimentation Platform
References
[1] S. Bubeck et al., “Sparks of Artificial General Intelligence: Early experiments with GPT-4”, https://doi.org/10.48550/arXiv.2303.12712.
[2] W. Machmouchi, A. H. Awadallah, I. Zitouni, and G. Buscher, “Beyond success rate: Utility as a search quality metric for online experiments,” in International Conference on Information and Knowledge Management, Proceedings, 2017, vol. Part F1318, doi: 10.1145/3132847.3132850.
Appendix
GPU Utilization Metrics
- Number of 429 responses (opens in new tab) received. A 429 error response is sent when the model and/or service is currently overloaded. We recommend measuring the 95th or 90th percentile of the number of 429 responses to measure the peak performance.
- Total number of tokens, computed as the sum of prompt tokens and completion tokens. This the main utilization metric we recommend for tracking for GPU Utilization. OpenAI charges based on the total number of tokens used by the prompt and response. (opens in new tab)
- Number of prompt tokens (opens in new tab). The number of tokens resulting from tokenizing the prompt passed to the LLM. While OpenAI also charges for these tokens, they are much cheaper (opens in new tab) than completion tokens and can be optimized by the product team.
- Number of completion tokens. Completion tokens (opens in new tab) are the largest cost incurred when using OpenAI models. These can be controlled by changing the Max_Tokens parameter (opens in new tab) in the request.
- Wasted Utilization per LLM. Some responses from the LLM will not provide any value to the user. This is due to issues such as truncation (see below), errors, “not able to understand” responses or other unactionable responses that can be defined based on the user scenario. We recommend tracking the number of completion tokens associated with these non-actionable or unused responses to keep them to a minimum.
- Number of LLM calls with truncated responses. If the API response has a “finish_reason”: “length (opens in new tab)”, it implies that the call reached the max_tokens limit set in the API request, so the response is likely truncated/incomplete.
Utility Metrics
User Engagement and Satisfaction
- Prompt and Response Funnel
- Number of opportunities to suggest content: This captures all instances where the LLM was called, irrespective of whether the response was shown to the user. This is important in case there is an added layer or orchestrator between the LLM and the feature that determines whether the response is in fact shown to the user.
- Number and Rate of prompts made to LLM
- Number and Rate of response from LLM
- Number and Rate of responses seen by user: As mentioned earlier, it’s possible not all responses are shown to the user due to content moderation, relevance or performance.
- Number and Rate of accepts by user: How to identify accepts depends on the user scenario. In a text prediction or summarization scenario, the user accepts the responses by including it in the document or text they are writing. In a conversational context, an accept is when a user thumbs up a response, gets positive utility from a link provided or reengages with the bot for more information.
- Number and Rate of responses kept (retained) by user at end of time X: This metric is particularly relevant in the context of text prediction where the user keeps the content and uses it in the doc or text they are creating.
- Prompt and Response Quality
- Average length of the prompts and responses
- Average time between prompts and between responses
- Time spent on writing prompts and on generating responses
- Average edit distance (opens in new tab) between prompts: Edit distance has long been used in information retrieval as a measure of reformulating queries and hence restating user intent. The more often a user reformulates a query or prompt, the more likely it is that the original prompt or query did not provide the information they are looking for. Note that since prompts can be changed or expanded by the product beyond what the user inputs, it’s important to also separate user and product components of the prompt. Moreover edit distance metrics require some data cooking for efficient computation.
- Average edit distance (opens in new tab) between LLM response and retained content: this is applicable in text prediction or summarization scenarios where the user can accept a response and edit it to fit their needs. For other scenarios and content types, you will need to tailor the definition of edit distance.
- Number of responses with Thumbs Up/Thumb Down feedback from the user: such metrics are explicit feedback from the user on how well the LLM response answered their prompt. However, these metrics, like other user sentiment metrics, suffer from low sample size and selection bias, as users who provide such feedback are not representative of the whole population.
- Retention: The following metrics can be averaged across users, sessions, days or any other unit as needed by the product.
- LLM conversation (opens in new tab) length and duration
- Average number of LLM conversations
- Average Number of days an LLM feature was actively used.
- Daily Active LLM users
- Retention rate of new-to-LLM users
- New users who use an LLM feature in their first session
Increase in productivity for collaboration scenarios
For scenarios where content can be created with AI and then consumed by users, we also recommend measuring any increase or improvement in productivity, both on the creation and consumption side.
Creator Productivity (better content created in less time)
As content creation becomes easier with LLMs, more creators will edit more documents faster and the quality of the content should improve.
- Reach of the content:
- #users, #sessions creating content per document
- #documents edited with the LLM
- Quality of the content – the length and richness of the prompts and responses created automatically and overall:
- Total characters retained per user
- Number and length of interactions with the LLM
- Number of total and user edits
- Number of artifacts used like images, charts
- Effort:
- Average time spent by user in editing mode.
Consumer Productivity (better consumption of content in less time):
- Reach of the content
- # users, #sessions consuming content per document
- # documents read that were edited with the LLM
- Quality of the content
- # consumption actions (e.g. sharing, commenting, reviewing) per AI-edited document
- Effort:
- Average time spent in consumption mode per document per user