Overview
New! Dryad and DryadLINQ are now available in source form at the Dryad GitHub repository (opens in new tab), with pre-built binaries available from NuGet.org (opens in new tab). For release documentation see our Getting Started with DryadLINQ (opens in new tab) page.
Most of the information below is historical and will be updated over time and migrated to the DryadLINQ documentation (opens in new tab) site.
Dryad is an infrastructure which allows a programmer to use the resources of a computer cluster or a data center for running data-parallel programs. A Dryad programmer can use thousands of machines, each of them with multiple processors or cores, without knowing anything about concurrent programming.
The Structure of Dryad Jobs
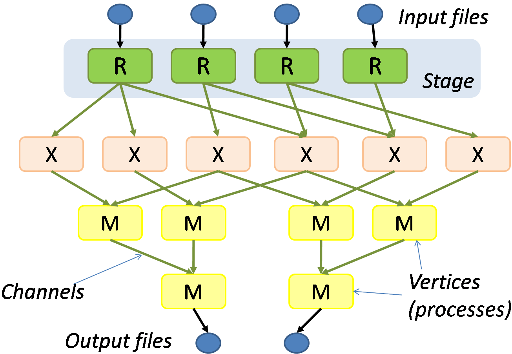
A Dryad programmer writes several sequential programs and connects them using one-way channels. The computation is structured as a directed graph: programs are graph vertices, while the channels are graph edges. A Dryad job is a graph generator which can synthesize any directed acyclic graph. These graphs can even change during execution, in response to important events in the computation.
Dryad is quite expressive. It completely subsumes other computation frameworks, such as Google’s map-reduce, or the relational algebra. Moreover, Dryad handles job creation and management, resource management, job monitoring and visualization, fault tolerance, re-execution, scheduling, and accounting.
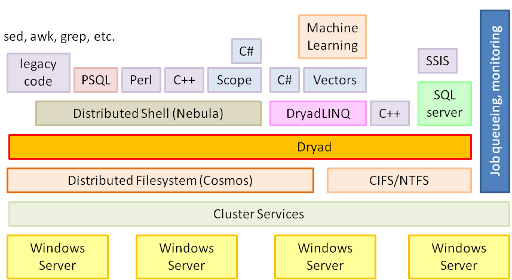
The Dryad Software Stack
As a proof of Dryad’s versatility, a rich software ecosystem has been built on top Dryad:
- SSIS on Dryad executes many instances of SQL server, each in a separate Dryad vertex, taking advantage of Dryad’s fault tolerance and scheduling. This system is currently deployed in a live production system as part of one of Microsoft’s AdCenter (opens in new tab) log processing pipelines.
- DryadLINQ generates Dryad computations from the LINQ (opens in new tab) Language-Integrated Query extensions to C#.
- The distributed shell is a generalization of the pipe concept from the Unix shell in three ways. If Unix pipes allow the construction of one-dimensional (1-D) process structures, the distributed shell allows the programmer to build 2-D structures in a scripting language. The distributed shell generalizes Unix pipes in three ways:
- It allows processes to easily connect multiple file descriptors of each process — hence the 2-D aspect.
- It allows the construction of pipes spanning multiple machines, across a cluster.
- It virtualizes the pipelines, allowing the execution of pipelines with many more processes than available machines, by time-multiplexing processors and buffering results.
- Several languages are compiled to distributed shell processes. PSQL is an early version, recently replaced with Scope.