
Sound Capture and Speech Enhancement
Producing clean audio signals in noisy environments
Summary
An important part of design for devices that contain microphones and loudspeakers is the acoustical design of the sound capture system. Any enclosure changes the directivity patterns of the microphones and their frequency response. Even with a well-designed sound capture system, the signal gets distorted by room noise and reverberation. The goal of device design is to overcome the device, room, and noise effects, ultimately producing a clean audio signal good enough for people and machines to understand.
Acoustic echo reduction
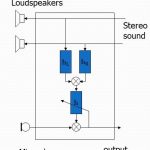
Acoustic echo cancellation, a straightforward application of adaptive filters, is one of the oldest signal processing algorithms. Being part of every speakerphone, it estimates the signal sent to the loudspeaker and captured by the microphone, and then subtracts it from the microphone channel. This results in a signal that contains only the speech in the room, which is called the near-end signal. For many years, stereo acoustic echo cancellation was not considered theoretically possible, with many scientists trying to find a solution good enough for engineering purposes. We solved this problem in 2011, by designing the first surround sound echo canceller in the industry, and then productizing it as part of Kinect for Xbox 360.
A typical audio pipeline includes another component: the echo suppressor. It works by applying a suppression gain, based on the estimation of the proportion of the echo residual to the desired signal. This non-linear processing is complementary to linear acoustic echo cancellation.
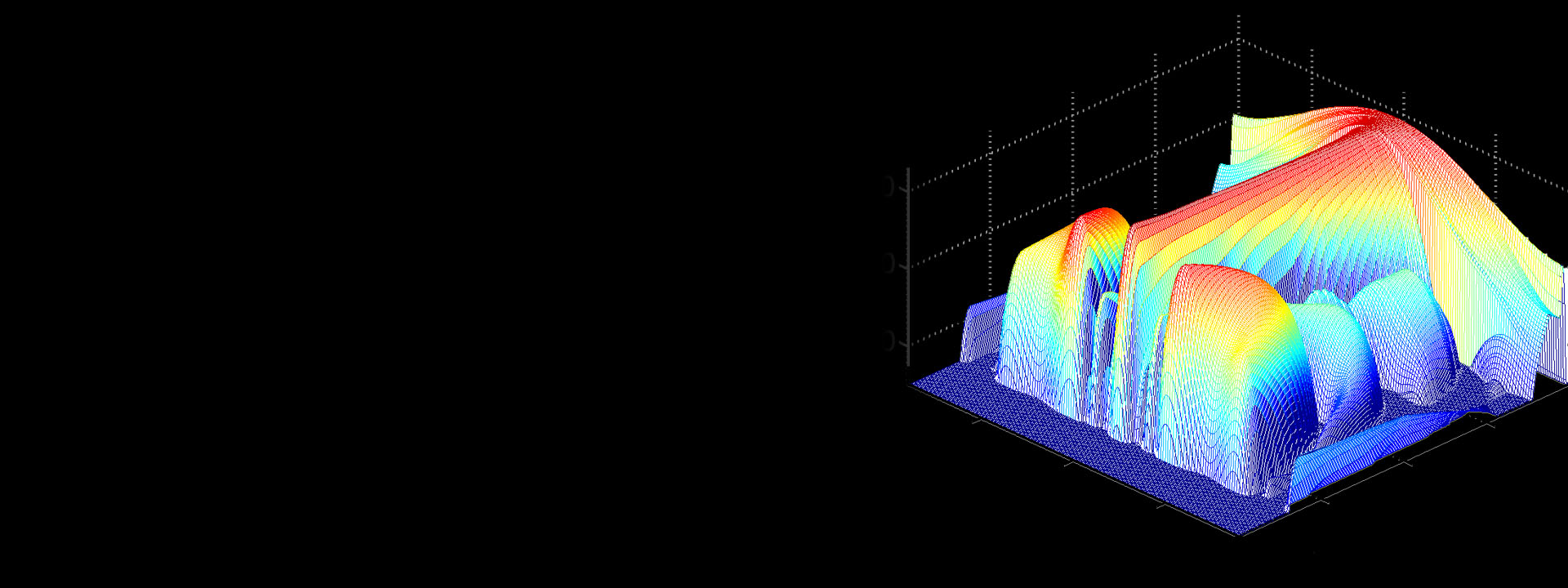
Microphone array processing
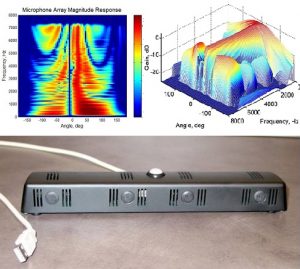
Given multiple microphones, called a microphone array, we can combine the microphone signals using a technology called beamforming. The resulting signal contains the speech coming from the desired direction and reduces noise, reverberation and other speech signals coming from other directions, increasing the understandability of the words. The beamformer converts the microphone array into a software-controlled directional microphone: The listening direction can be electronically steered by the way we mix the signals from the microphone, pointing to the desired sound source when it changes its position or another person starts to talk. An integral part of the microphone array processor is the sound source localizer: It determines the direction of either the dominant sound source or even multiple sound sources, and points a beam towards it. The sound source localizer needs to address both noise and reverberation challenges.
Complementary to linear beamforming is suppression gain-based spatial filtering. The gain is estimated based on the direction of the sound in every frequency bin in every frame – higher if it comes from the desired direction, lower if it is away from it.
This technology has been integrated into Microsoft RoundTable device, Kinect for Xbox, and Microsoft HoloLens for better capture of the speaker’s voice.
Noise reduction
In any given mixture of speech and noise, a noise suppressor is used to estimate and identify the clean speech signal. Classic signal processing-based methods used assumptions on the statistical distributions and stationarity of speech and noise signals. While these techniques worked well in practice for stationary noise, novel advancements in machine learning (ML) and artificial intelligence (AI) provides us even more powerful tools for implementing ML-based noise suppressors. Although ML-based techniques achieve already impressive results, a lot of research is needed to find efficient and robust models for real-time processing on resource-constrained devices without degrading the audio quality.
Technology transfers
Over the past years, our group has transferred multiple algorithms and code for speech enhancement to Microsoft products. Notable examples include:
- Microsoft HoloLens (opens in new tab) and Microsoft HoloLens 2: speech enhancement audio processing pipeline for capturing the wearer’s voice and environmental audio.
- Windows 10: speech enhancement audio pipeline, including support of microphone arrays with arbitrary geometry.
- Kinect for Windows (opens in new tab): the software development kit contains a light version of the audio pipeline for Kinect. Read more about the history of the device here (opens in new tab).
- Kinect for Xbox 360 (opens in new tab) and Kinect for Xbox One (opens in new tab): speech enhancement audio pipeline. This was the first audio pipeline in the industry to support surround sound echo cancellation and hands-free distant speech recognition.
- Microsoft Auto Platform (opens in new tab): algorithms for speech enhancement.
- Windows Vista (opens in new tab): microphone array support for five preselected geometries.
- Microsoft RoundTable (opens in new tab) device: algorithms for speech enhancement.
