


Audio and acoustics



Publication
Large-Scale Automatic Audiobook Creation
Video
HyWay: Physical Walk (MSR India – TAB Feb 2023)
A key aspect of attending such an event in person is being able to experience the setting in its fullness — hearing the buzz of background conversations and seeing who is around. This can be…

Microsoft Research Blog
Research Focus: Week of August 14, 2023
In this issue: HyWay enables hybrid mingling; Auto-Tables transforms non-relational tables into standard relational forms; training dense retrievers to identify high-quality in-context examples for LLM; improving pronunciation assessment in CAPT.

Publication
Audio Retrieval with WavText5K and CLAP Training
Microsoft Research Blog
Thinking beyond audio: Augmenting headphones for everyday digital interactions
Because headphones rank among the most popular wearables in the market, we have an exciting opportunity to expand their capabilities through integrating existing sensors with supplementary ones to enable a wide variety of experiences that…

Microsoft Research Blog
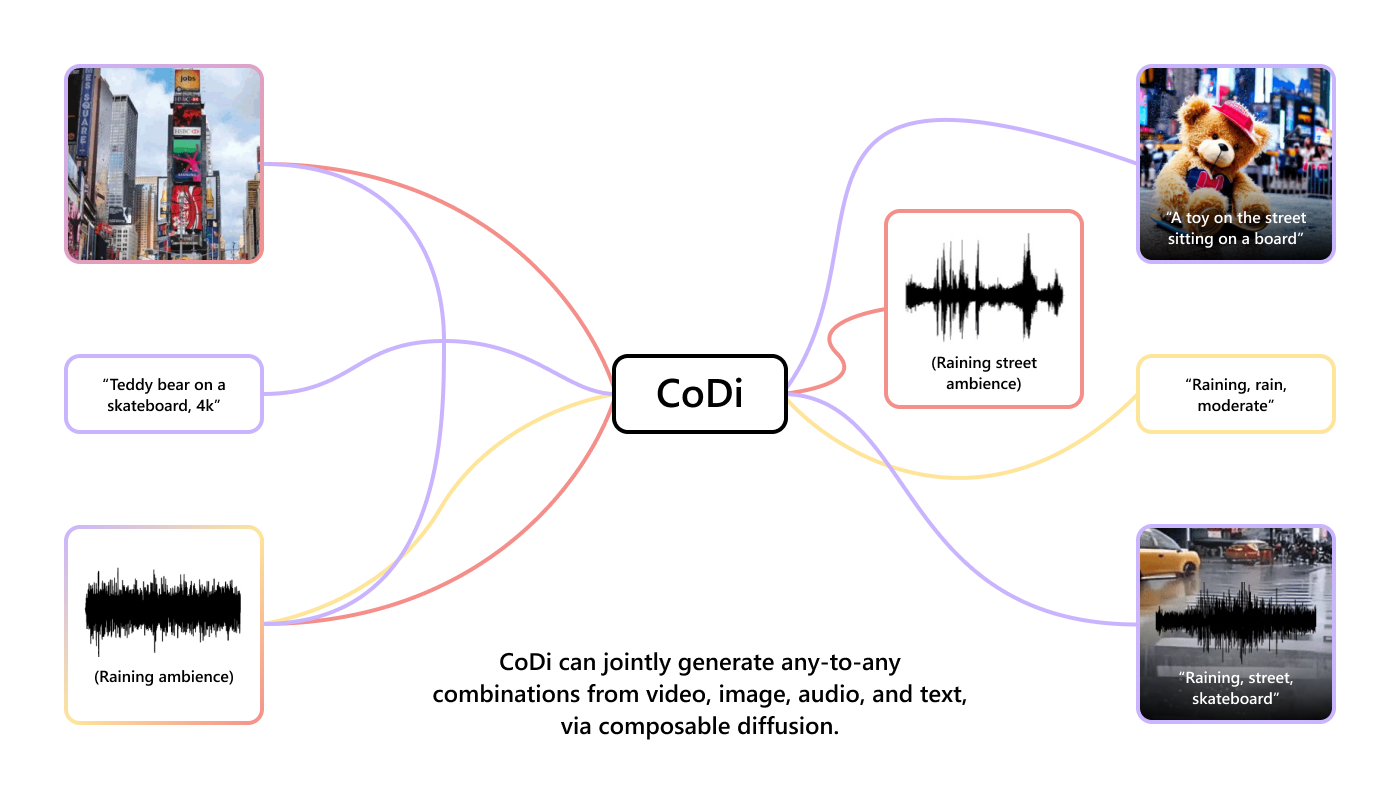
Breaking cross-modal boundaries in multimodal AI: Introducing CoDi, composable diffusion for any-to-any generation
Imagine an AI model that can seamlessly generate high-quality content across text, images, video, and audio, all at once. Such a model would more accurately capture the multimodal nature of the world and human comprehension,…
Project
VALL-E
Neural codec language models for speech synthesis We introduce a language modeling approach for text-to-speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural…