
Object recognition systems have made spectacular advances in recent years, but they rely on training datasets with thousands of high-quality, labelled examples per object category. Learning new objects from only a few examples could open the door to many new applications. For example, robotics manufacturing requires a system to quickly learn new parts, while assistive technologies need to be adapted to the unique needs and abilities of every individual.
Few-shot learning aims to reduce these demands by training models that can recognize completely novel objects from only a few examples, say 1 to 10. In particular, meta-learning algorithms—which ‘learn to learn’ using episodic training—are a promising approach to significantly reduce the number of training examples needed to train a model. However, most research in few-shot learning has been driven by benchmark datasets that lack the high variation that applications face when deployed in the real world.
In partnership with City, University of London, we introduce the ORBIT dataset and few-shot benchmark for learning new objects from only a few, high-variation examples to close this gap. The dataset and benchmark set a new standard for evaluating machine learning models in few-shot, high-variation learning scenarios, which will help to train models for higher performance in real-world scenarios. This work is done in collaboration with a multi-disciplinary team, including Simone Stumpf (opens in new tab), Lida Theodorou (opens in new tab), and Matthew Tobias Harris (opens in new tab) from City, University of London (opens in new tab) and Luisa Zintgraf (opens in new tab) from University of Oxford (opens in new tab). The work was funded by Microsoft AI for Accessibility. You can read more about the ORBIT research project and its goal to make AI more inclusive of people with disabilities in this AI Blog post (opens in new tab).
PODCAST SERIES

AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
You can learn more about the work in our research papers: “ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition,” published at the International Conference of Computer Vision (ICCV 2021), and “Disability-first Dataset Creation: Lessons from Constructing a Dataset for Teachable Object Recognition with Blind and Low Vision Data Collectors,” published at the 23rd International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS 2021).
You’re also invited to join Senior Researcher Daniela Massiceti for a talk about the ORBIT benchmark dataset and harnessing few-shot learning for teachable AI at the first Microsoft Research Summit (opens in new tab). Massiceti will be presenting “Bucket of me: Using few-shot learning to realize teachable AI systems” as part of the Responsible AI track on October 19. To view the presentation on demand, register at the Research Summit event page.
The ORBIT benchmark dataset contains 3,822 videos of 486 objects recorded by 77 people who are blind or low vision using their mobile phones—a total of 2,687,934 frames. Code for loading the dataset, computing benchmark metrics, and running baselines is available at the ORBIT dataset GitHub page (opens in new tab).
Inspired by teachable object recognizers
The ORBIT dataset and benchmark are inspired by a real-world application for the blind and low-vision community: teachable object recognizers. These allow a person to teach a system to recognize objects that may be important for them by capturing just a few short videos of those objects. These videos are then used to train an object recognizer that is personalized. This would allow a person who is blind to teach the object recognizer their house keys or favorite shirt, and then recognize them with a phone. Such objects cannot be identified by typical object recognizers as they are not included in common object recognition training datasets.
Teachable object recognition is an excellent example of a few-shot, high-variation scenario. It’s few-shot because people can only capture a handful of short videos recorded to “teach” a new object. Most current machine learning models for object recognition require thousands of images to train. It’s not feasible to have people submit videos at that scale, which is why few-shot learning is so important when people are teaching object recognizers from their own videos. It’s high-variation because each person has only a few objects, and the videos they capture of these objects will vary in quality, blur, centrality of object, and other factors as shown in Figure 2.

Human-centric benchmark for teachable object recognition
While datasets are fundamental for driving innovation in machine learning, good metrics are just as important in helping researchers evaluate their work in realistic settings. Grounded in this challenging, real-world scenario, we propose a benchmark on the ORBIT dataset. Unlike typical computer vision benchmarks, performance on the teachable object recognition benchmark is measured based on input from each user.
This means that the trained machine learning model is given just the objects and associated videos for a single user, and it is evaluated by how well it can recognize that user’s objects. This process is done for each user in a set of test users. The result is a suite of metrics that more closely captures how well a teachable object recognizer would work for a single user in the real world.
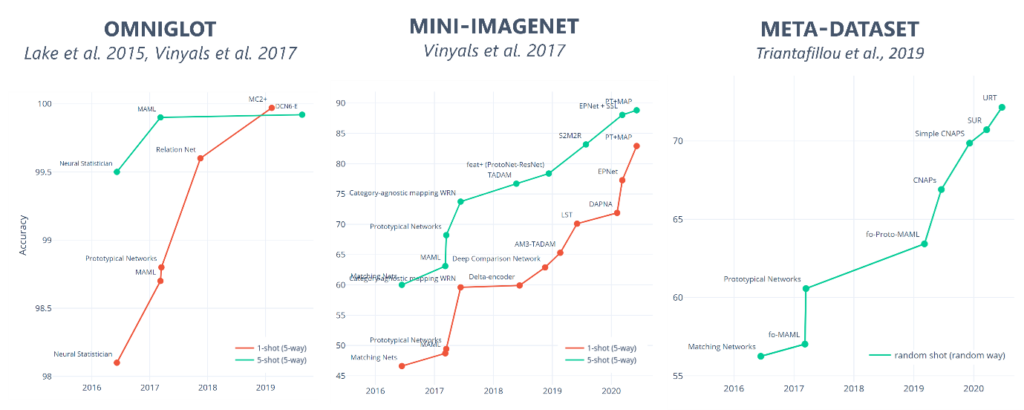
Evaluations on highly cited few-shot learning models show that there is significant scope for innovation in high-variation, few-shot learning. Despite saturation of model performance on existing few-shot benchmarks, few-shot models only achieve 50-55% accuracy on the teachable object recognition benchmark. Moreover, there is a high variance between users. These results illustrate the need to make algorithms more robust to high-variation (or “noisy”) data.

Research to realize human-AI collaboration
Creating teachable object recognizers presents challenges for machine learning beyond object recognition. One example of a challenge posed by a human-centric task formulation is the need for the model to provide feedback to users about the data they provided when training in a new personal object. Is it enough data? Is it good-quality data? Uncertainty quantification is an area of machine learning that can contribute to solving this challenge.
Moreover, the challenges in building teachable object recognition systems go beyond machine learning algorithmic improvements, making it an area ripe for multi-disciplinary teams. Designing the feedback of the model to help users become better teachers requires a great deal of subtlety in user interaction. Supporting the adaptation of models to run on resource-constrained devices such as mobile phones is also a significant engineering task.
In summary, the ORBIT dataset and benchmark provide a rich playground to drive research in approaches that are more robust to few-shot, high-variation conditions, a step beyond existing curated vision datasets and benchmarks. In addition to the ORBIT benchmark, the dataset can be used to explore a wide set of other real-world recognition tasks. We hope that these contributions will not only have real-world impact by shaping the next generation of recognition tools for the blind and low-vision community, but also improve the robustness of computer vision systems across a broad range of other applications.