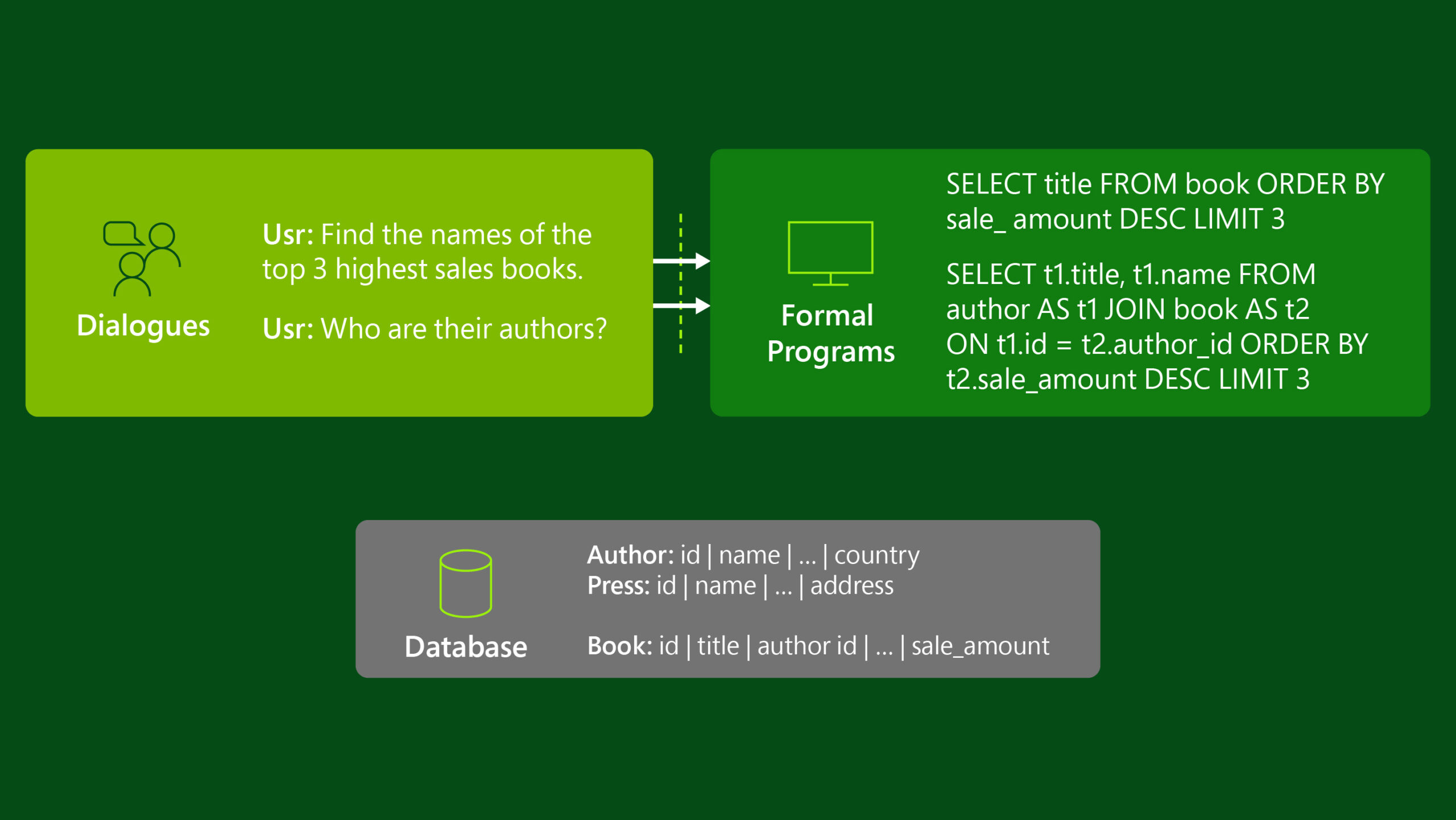
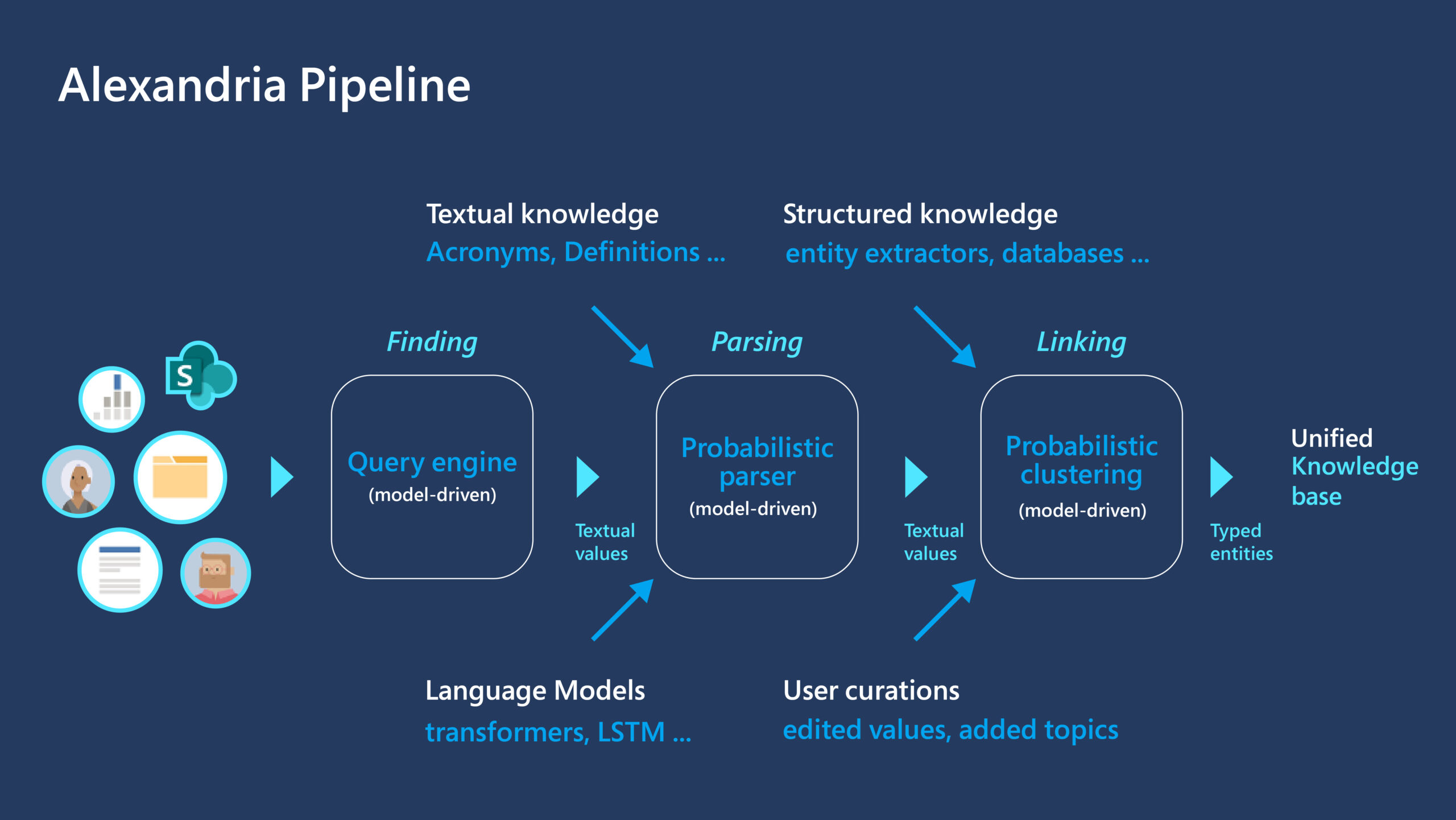
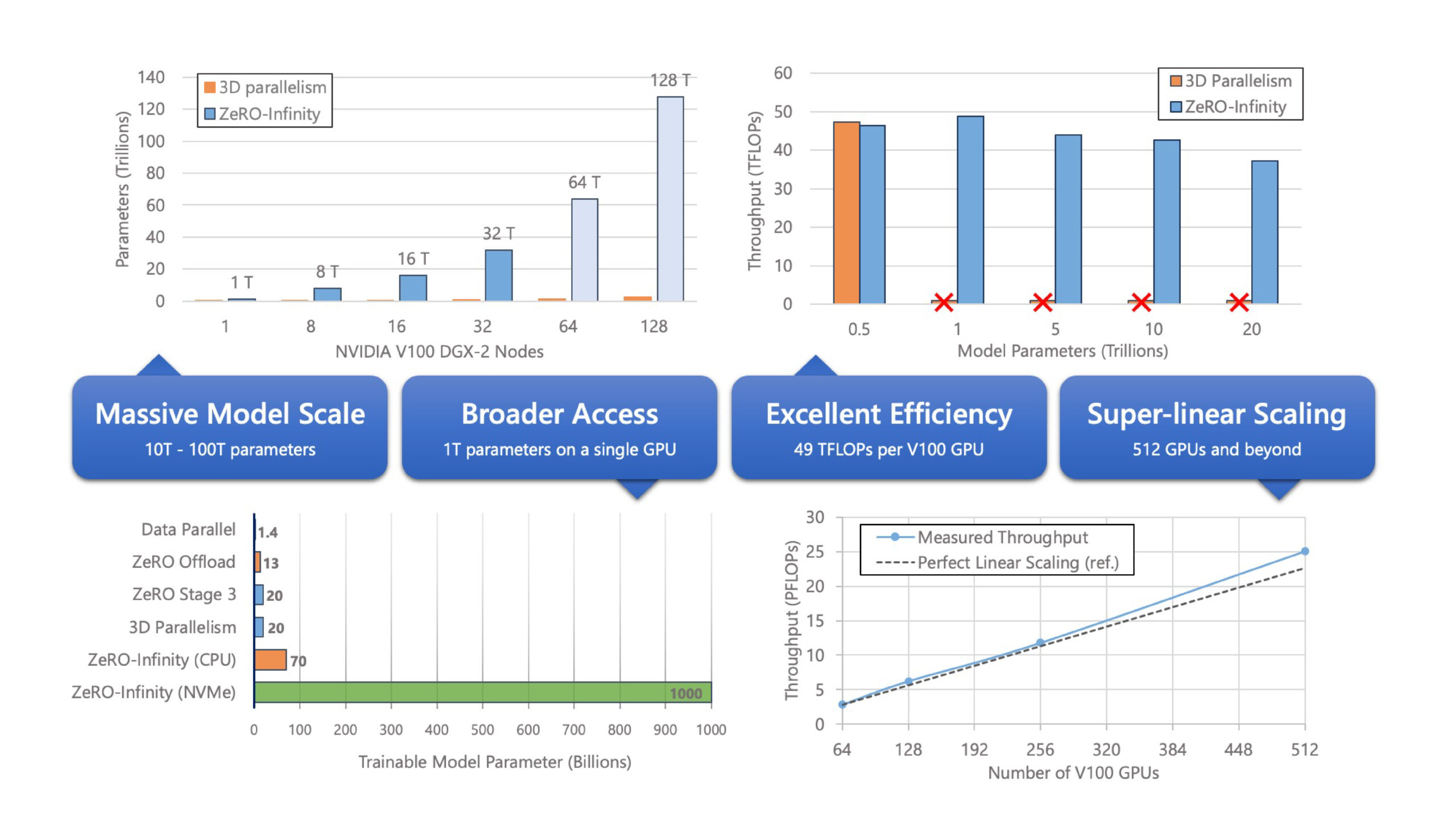
Microsoft and NVIDIA introduce parameter-efficient multimodal transformers for video representation learning
May 17, 2021 | Yale Song
Understanding video is one of the most challenging problems in AI, and an important underlying requirement is learning multimodal representations that capture information about objects, actions, sounds, and their long-range statistical dependencies from audio-visual signals. Recently, transformers have been successful in vision-and-language tasks such as image…