

Recent methods in artificial intelligence enable AI software to produce rich and creative digital artifacts such as text and images painted from scratch. One technique used in creating these artifacts are generative adversarial networks (GANs). Today at NIPS 2017 (opens in new tab), researchers from Microsoft Research and ETH Zurich present their work on making GAN models more robust and practically useful.
Generative adversarial networks are a recent breakthrough in machine learning. Initially proposed by Ian Goodfellow and colleagues at the University of Montreal (opens in new tab) at NIPS 2014, the GAN approach enables the specification and training of rich probabilistic deep learning models using standard deep learning technology.
“In the past, one challenge in using GAN models has been the difficulty of training them reliably; our work represents a step forward in making GANs simpler to train.”
~ Thomas Hofmann, Professor, ETH Zurich
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Allowing for flexible probabilistic models is important in order to capture rich phenomena present in complex data. For example, even a low-resolution image has tens of thousands of pixel observations and contains structure at several scales, from correlated neighboring pixels, to edges, to objects, to scene-level statistics. Machine learning models trained on images need to capture this multileveled structure to effectively reason about image content.
Deep learning models successfully capture such structure in their input; for example, in 2012, researchers from Toronto produced the famous AlexNet (opens in new tab) network for image recognition, and later Microsoft ResNet (opens in new tab) could reliably understand images and classify them at human-level accuracy.
However, while these systems are good at understanding image content, before GANs arrived, it was not possible to produce images or generate similarly rich outputs. In a sense, it was not possible for machine learning models to be creative and create complex observations such as entire images.
How generative adversarial networks work
GANs learn to generate content by playing a two-player game between a generator network and an adversary network. The generator network transforms a set of random numbers through a neural network into an observation, such as an image. Each generated instance is then checked by the adversary, which makes a decision as to whether the sample is “real” or “fake.” The adversary is able to distinguish real samples from fake samples because it is also provided with a reference data set of real samples.
Both the generator and the adversary play the same game but with different goals: the generator tries to fool the adversary, and the adversary tries to remain accurate in identifying samples from the generator.
When playing this game over time, both players learn and, by the end, the generator network can create realistic instances similar to the reference data.
In research presented at NIPS last year, researchers from Microsoft generalized the above interpretation of GANs to a broader class of games, providing a deeper theoretical understanding of the GAN learning objective and enabling GANs to apply to other machine learning problems such as probabilistic inference.
Problems in training GANs
Despite the excitement around GANs, back at NIPS 2016 the situation looked bleak: GANs remained notoriously difficult to train and the reasons for these difficulties were not fully clear.
Given a new problem, it was difficult to predict whether a GAN would work and typical failure modes included the collapse of the entire generator to a trivial solution of producing the same output over and over — demonstrating no creativity at all!
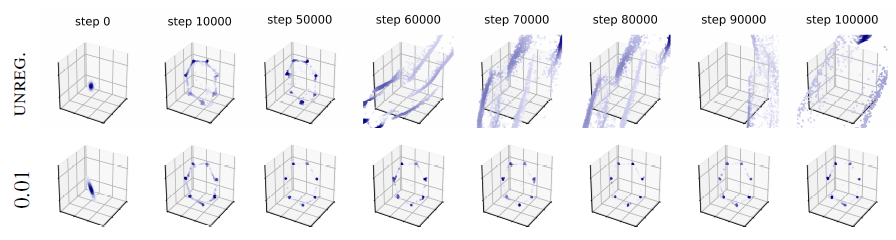
We make this problem visible in the following figure, where we visualize the training process of a normal GAN model.

Explaining and fixing the difficulties of training GANs was one of the main problems discussed at the NIPS 2016 workshop on adversarial training (opens in new tab), and solutions such as unrolling the GAN game (opens in new tab), additional stability objectives as in CVAE-GANs and minibatch discrimination, label smoothing and other heuristics (opens in new tab) have been put forth by the leading researchers.
However, one key difficulty in training GANs is the issue of dimensional misspecification: a low-dimensional input is mapped continuously to a high-dimensional space. As a result, GANs summarize the distribution via a low-dimensional manifold but do not accurately capture the full training distribution. The situation is illustrated in the following figure, where a one-dimensional input is mapped onto a two-dimensional distribution.
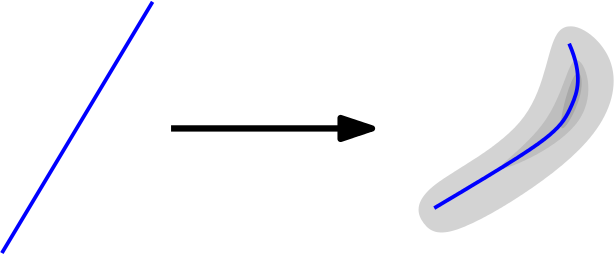
Dimensional misspecification was concurrently identified as a key problem in GANs by researchers at Twitter (opens in new tab) and researchers at New York University (opens in new tab).
Their fix is to add random perturbations to any instance before handing it to the adversary. This fix is simple to implement and practically useful; however, by adding additional noise to each input, the training signal now contains additional variance and learning slows down or — for high enough noise variance — breaks down completely.
Stabilizing GANs
In the work presented today at NIPS 2017, the problem of noise variance is overcome, as presented in a paper entitled Stabilizing Training of Generative Adversarial Networks through Regularization by Kevin Roth, Aurelien Lucchi, Sebastian Nowozin and Thomas Hofmann (opens in new tab).
These four researchers collaborate on a project called “Tractable by Design” as part of the Microsoft Research Swiss Joint Research Centre (Swiss JRC in short), with Kevin Roth’s PhD studies being supported through the Swiss JRC.
The technical contribution of the work is to derive an analytic approximation to the addition of noise and showing that this corresponds to a particular form of regularization of the variation of functions.
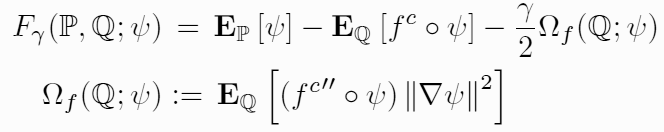
The first equation represents the f-GAN training objective with an additional regularization term.
The second equation shows the form of the regularization term, incorporating the variation of the discriminator function, weighted by a function depending on the particular f-divergence being used.
Adding this regularizer immediately stabilizes the training of GAN models as shown in the figure below.
In principle, the regularization technique is not new; it was proposed originally in 1995 by professor Chris Bishop, now lab director at Microsoft Research Cambridge. The technique’s result shows that by making training data more variable through adding noise, one really encodes a preference that the learned machine learning system should depend in a smooth way on its input. That is, that it should be robust to small variations.
The work presented today is a milestone because it addresses a key open problem in a line of research on generalizing GANs with a simple and principled solution. The work also establishes connections to different approaches aimed at improving GAN models, such as gradient regularization in Wasserstein GANs (opens in new tab) and to a numerical stability analysis, the latter work also involving researchers from Microsoft.
The work also extends the applicability of GAN models to larger deep learning architectures. In the following figure, we show a comparison of a network generating face images using the ResNet architecture. On the left, the network is trained without regularization, and on the right, the network is trained with regularization.
The quality of samples is clearly improved through the addition of regularization.
We believe that GAN models will be widely used beyond perceptual domains such as image generation. Toward this end, Microsoft Research is committed to the research to make GAN models more practical and applicable to more areas of study.
Related: