

Artificial intelligence technologies hold great promise as partners in the real world. They’re in the early stages of helping doctors administer care to their patients and lenders determine the risk associated with loan applications, among other examples. But what happens when these systems that users have come to understand and employ in ways that will enhance their work are updated? Sure, we can assume an improvement in accuracy or speed on the part of the agent, a seemingly beneficial change. However, current practices for updating the models used to power AI partners don’t account for how practitioners have learned over time to trust and make use of an agent’s contributions.
Our team—which also includes graduate student Gagan Bansal; (opens in new tab)Microsoft Technical Fellow Eric Horvitz; University of Washington professor Daniel S. Weld (opens in new tab); and University of Michigan assistant professor Walter S. Lasecki (opens in new tab)—focuses on this crucial step in the life cycle of machine learning models. In the work we’re presenting next week at the Association for the Advancement of Artificial Intelligence’s annual conference (AAAI 2019) (opens in new tab), we introduce a platform, openly available on GitHub, to help better understand the human-AI dynamics in these types of settings (opens in new tab).
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Updates are usually fueled and motivated either by additional training data or by algorithmic and optimization advances. Currently, an upgrade to an AI system is informed by improvements in model performance alone, often measured in terms of empirical accuracy on benchmark datasets. These traditional metrics on performance of the AI component are not sufficient when the AI technology is used by people to accomplish tasks. Since models sometimes make mistakes, the success of human-AI teams in decision-making relies on the human partner to create a mental model and to learn when to trust the machine so that he or she can successfully decide whether to override a decision. We show in the research we’ll be sharing at AAAI that updates that are not optimized for human-AI teams can cause significant disruptions in the collaboration by violating human trust.
Imagine a doctor using a diagnosis model she has found to be most helpful in cases involving her older patients. Let’s say it’s been 95 percent accurate. After an update, the model sees an overall increase in accuracy for all patients, to 98 percent, but—unbeknownst to the doctor—it introduces new mistakes that lead to poorer performance when applied to older patients. Even though the model has improved, the doctor may take a wrong action, leading to a lower team performance. In fact, through human studies we present in the paper, we show that an update to a more accurate machine-learned model that is incompatible with the mental model of the human user—that is, an updated model making errors on specific cases the previous version was getting right—can hurt team performance instead of improving it. This empirical result provides evidence for undertaking a more comprehensive optimization—one that considers the performance of the human-AI team rather than the performance of only the AI component.
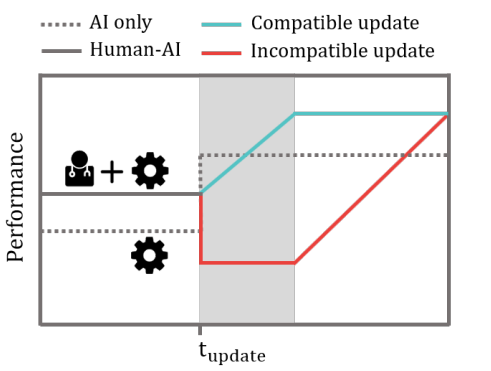
Figure 1: Human-AI teams perform better than either team member alone, but when the AI component is updated, its behavior may violate human expectations. Even if updates increase the AI’s individual performance, they may reduce team performance by making mistakes in regions where humans have learned to trust the AI.
Toward compatible updates
Preferably, we’d like to employ models that have the best accuracy on the given prediction task and are also fully compatible with their previous versions, free of any new errors that break user trust. This calls for the previous version to be included in the mathematical optimization of the new model. So far, traditional loss functions attempt to approximate empirical accuracy alone. By incorporating in the loss function the compatibility with the previous model—and therefore compatibility with the potential previous user experience—we aim to minimize update disruption for the whole team. Technically, the loss function is augmented by a dissonance factor that measures the divergence of models for data points where the old model was correct, penalizing newly introduced errors.
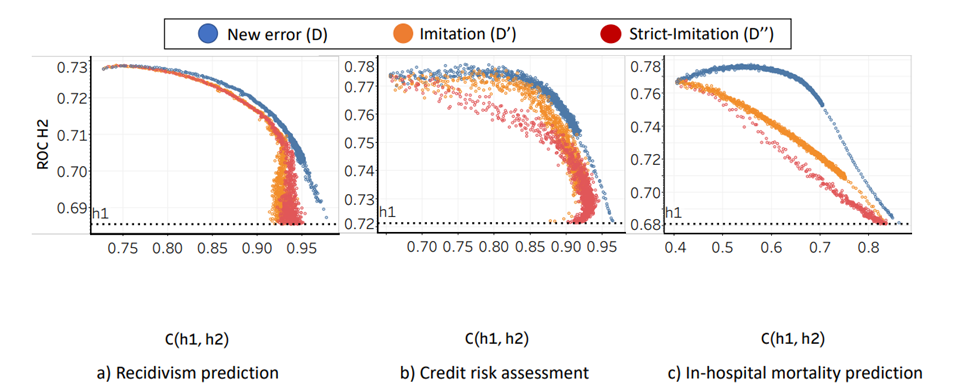
Figure 2: Performance of the updated model (ROC H2) versus compatibility with previous version (C(h1, h2)) for a logistic regression classifier. The reformulated training objective offers an explorable performance/compatibility tradeoff, which in this case is more forgiving over the first half of the curves. Each curve—new error, imitation and strict-imitation—represents a different formulation of the dissonance function, further described in the paper.
In practice, full compatibility and perfect accuracy improvements are hard to achieve. To assist machine learning practitioners in selecting the model best suited for their use case, we propose visualizations that allow engineers to explore the performance/compatibility tradeoff by varying the weight assigned to the dissonance factor in the loss function. Based on results on datasets from three different real-world high-stake domains, we show the tradeoff curves are generally more flexible (flat) in their first half as we increase the weight on the cost of incompatibility (see Figure 2). This demonstrates that, at the very least, we can choose to train and deploy a more compatible update without significant loss in accuracy. In these cases, a more compatible update would also reduce the effort of user retraining. When the sacrifice in accuracy becomes too great to justify, any resulting negative outcomes from the tradeoff in compatibility will require efficient explanation techniques that can help users better understand how the model has changed.
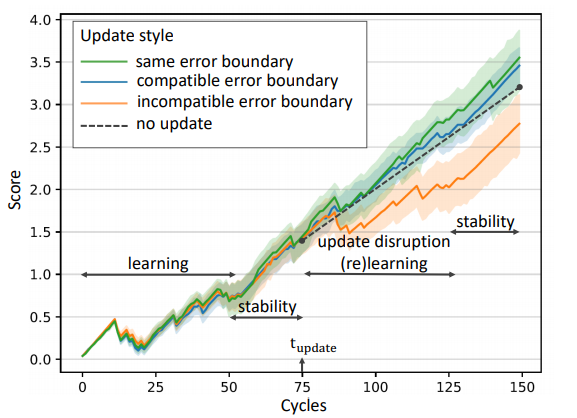
Figure 3: Graph reporting human-AI teamwork performance as a function of time in collaboration. User study experiments with the CAJA platform show that an update violating the learned user mental model (at cycle 75) deteriorates the team performance following the update.
CAJA: A tool for studying human-AI teams
Beyond the compatible updates problem, human-AI collaboration for decision-making poses multiple challenges at the intersection of human cognition, mathematical optimization, interpretability, and human-computer interaction. Comprehensive studies require experimenting with parameters such as the length of interaction, task and AI complexity, and the overall objective measuring the value of the interaction on real-world problems. To facilitate studies in this field, we developed the CAJA platform (opens in new tab), which supports user studies for tasks captured in an assembly line scenario. The platform abstracts the specifics of problem-solving and focuses on understanding the effect of mental modeling on team success. The tool is in its early phase; we plan to extend the platform so that it also supports collaboration in the presence of explanations and users with varying expertise. CAJA is designed to be used via external crowdsourcing platforms such as Amazon Mechanical Turk. Using this platform, we were able to show more accurate but incompatible updates can indeed hurt team performance while compatible updates leverage the algorithmic improvement by respecting the human mental model.
Developing AI systems that can be effective partners for human decision-makers will require innovations in the way we design and maintain AI systems, as well as further studies on human-AI teamwork. We hope that our AAAI paper and the CAJA platform will help facilitate further progress in this space.